Blog
Software Engineering, GNU/Linux, Data, GIS, and other things I like.
- New Website & Scala Days 2025 Announcement
2025-06-05: Some personal updates: My upcoming talk @ Scala Days 2025 in Lausanne, Switzerland, my new website, switching from Hugo, thoughts on the modern web & minimalism, and maintaining ink-free (for the ~2 people using my RSS feed).
scalafrontendgowebhugoastrodata engineering
- A Distributed System from scratch, with Scala 3 - Part 3: Job submission, worker scaling, and leader election & consensus with Raft
2025-05-18: Upgrades to Bridge Four, the functional, effectful distributed compute system optimized for embarrassingly parallel workloads: Updating Scala, auto-scaling workers, and implementing leader election with Raft (or half of a replicated state machine).
programmingscaladistributed systemsfunctional programmingcatscats-effecttagless finalhigher kinded typeszioraftbridgefour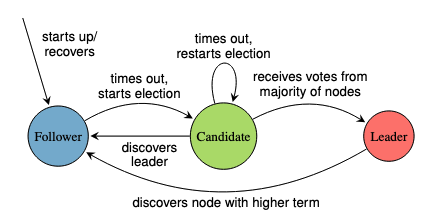
- My 2025 Homelab Updates: Quadrupling Capacity
2025-01-01: ...because everybody wants 40 cores, 256GB RAM, and 130TB storage. Some 2025 updates to my homelab, which might or might not be getting out of hand.
linuxservernetworkinghomelabzfsproxmoxhardware
- Why I still self host my servers (and what I've recently learned)
2024-08-25: A short story on why I still go through the effort of self hosting servers and some things it taught me recently.
linuxservernetworkinghomelabawsdistributed systemsproxmox
- Improving my Distributed System with Scala 3: Consistency Guarantees & Background Tasks (Part 2)
2024-02-19: Improving Bridge Four, a simple, functional, effectful, single-leader, multi worker, distributed compute system optimized for embarrassingly parallel workloads by providing consistency guarantees and improving overall code quality (or something like that).
programmingscaladistributed systemsfunctional programmingcatscats-effecttagless finalhigher kinded typesziobridgefour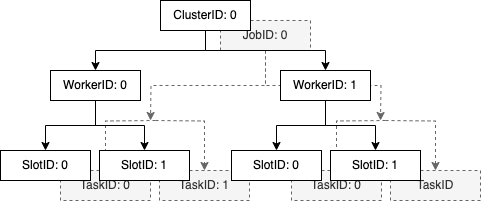
- Moving a Proxmox host with a SAS HBA as PCI passthrough for zfs + TrueNAS
2023-10-26: How to move a Proxmox host to a new m.2 SSD when using a LSI SAS HBA card to realize PCI passthrough for HDDs for zfs + TrueNAS.
linuxservernetworkingdebianproxmoxtruenaszfsluksbackups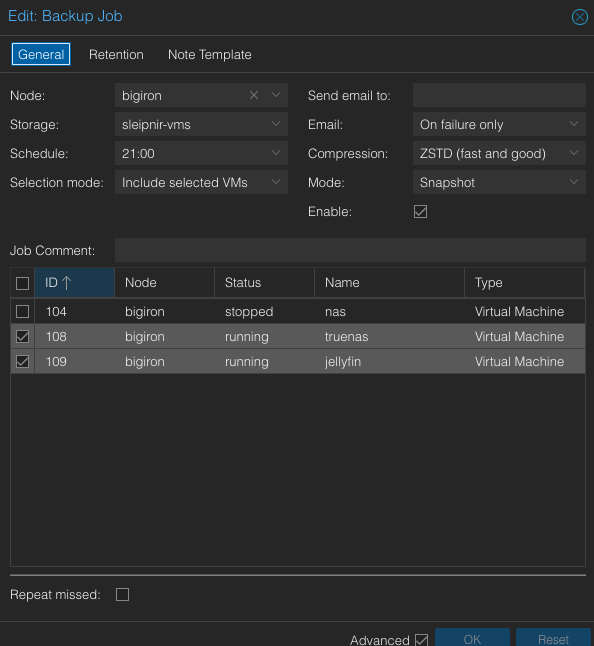
- Building a functional, effectful Distributed System from scratch in Scala 3, just to avoid Leetcode (Part 1)
2023-06-19: Building something that already exist (but worse) so I don't have to think about Leetcode: Bridge Four, a simple, functional, effectful, single-leader, multi worker, distributed compute system optimized for embarrassingly parallel workloads.
programmingscaladistributed systemsfunctional programmingcatscats-effecttagless finalhigher kinded typesziobridgefour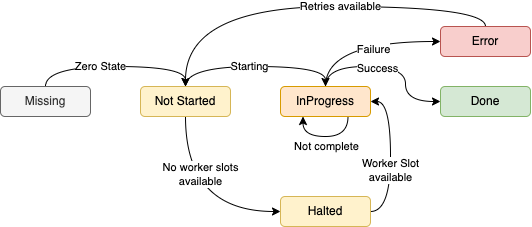
- Migrating a Home Server to Proxmox, TrueNas, and zfs, or: How to make your home network really complicated for no good reason
2023-04-08: Going from a single, bare metal Debian server to two physical machines, 7 VMS, 5 zfs pools, and a whole bunch of data and networking: An experience. Also, stuff broke.
linuxservernetworkingdebianproxmoxtruenaszfsluksbackups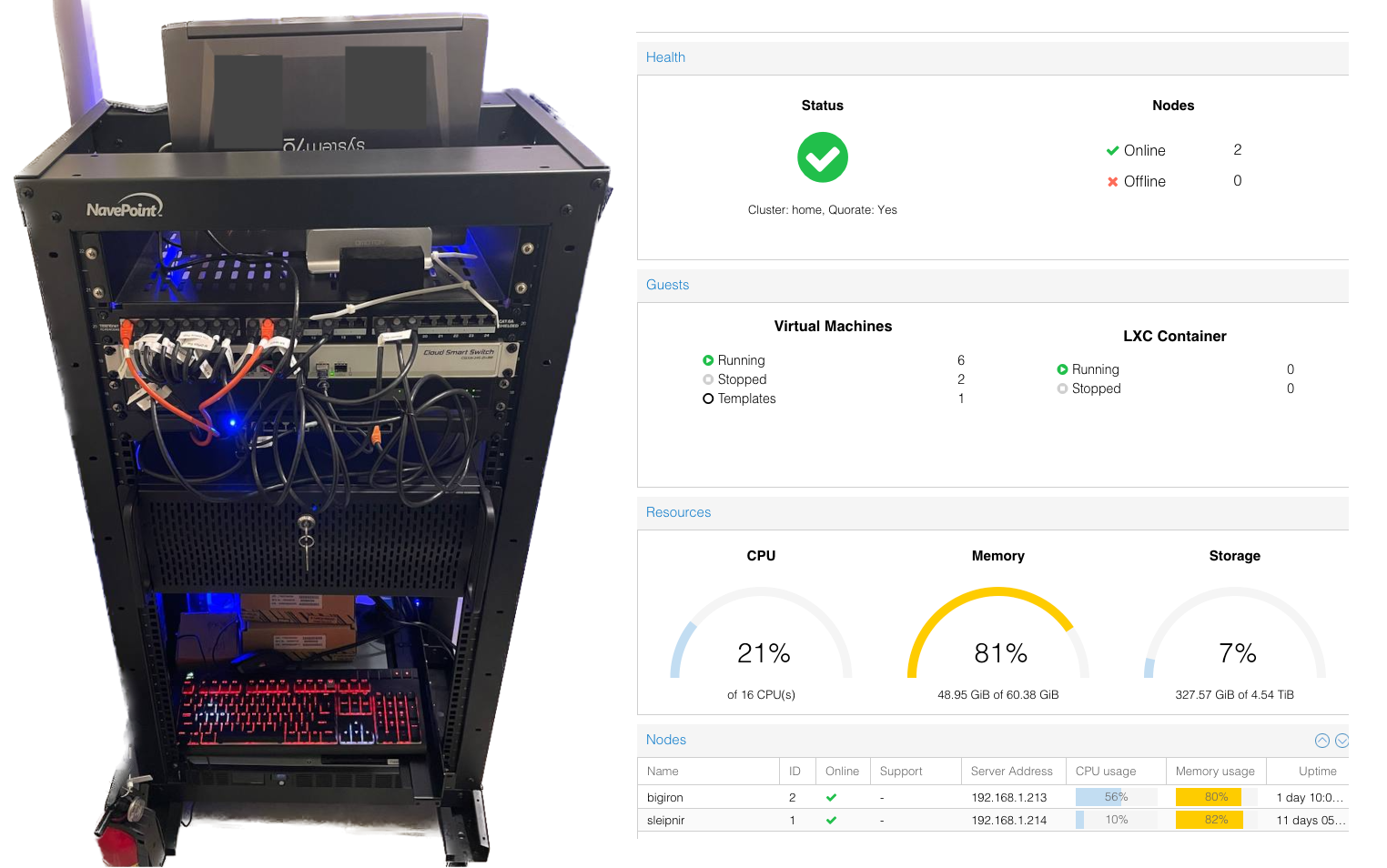
- QGIS is the mapping software you didn't know you needed
2023-01-24: QGIS is incredible: You can build maps that make use of the absolute wealth of public data out there and put Google Maps to absolute shame. This article is doing just that.
qgisgeospatialgpsopen sourcepython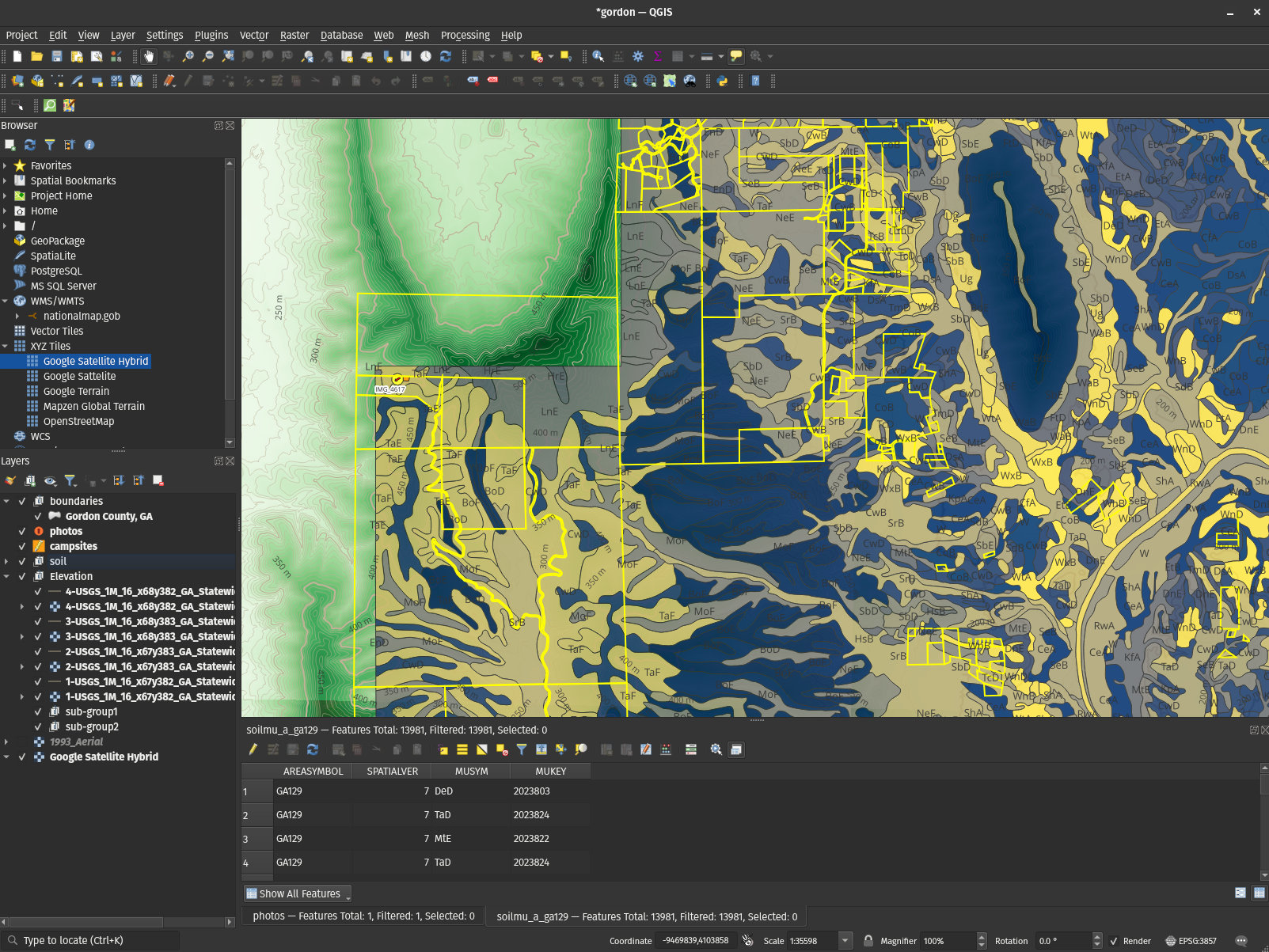
- Tiny Telematics: Tracking my truck's location offline with a Raspberry Pi, redis, Kafka, and Flink (Part 2)
2022-09-08: Tracking vehicle location offline with a Raspberry Pi, Part 2: Apache Flink, scala, Kafka, and road-testing.
scalaflinkkafkastreaminglinuxtelematicsgpstypesfunctional programming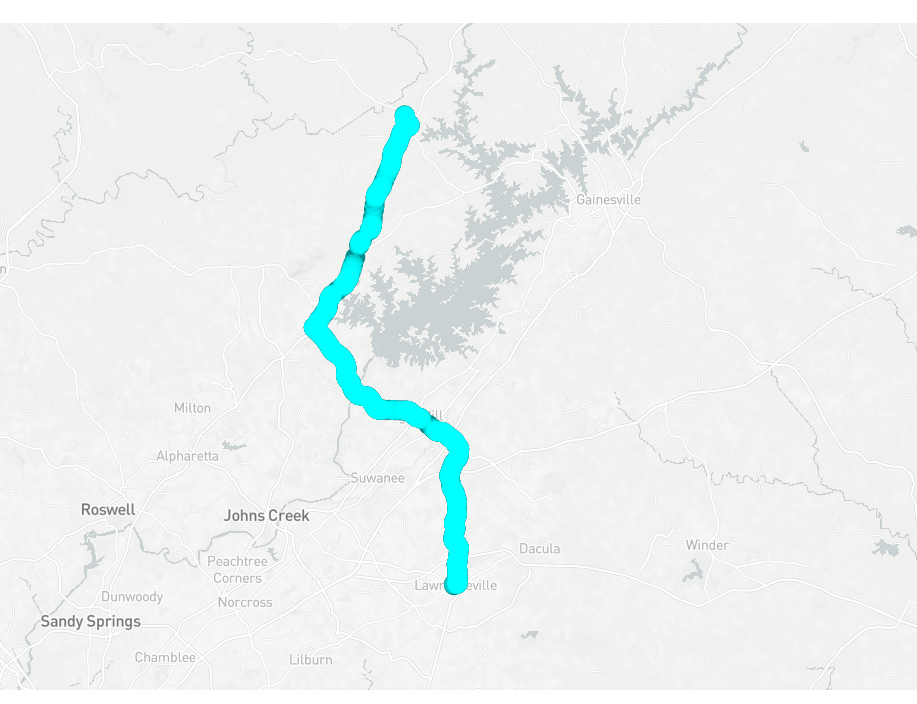
- Tiny Telematics: Tracking my truck's location offline with a Raspberry Pi, redis, Kafka, and Flink (Part 1)
2022-08-29: Building custom Linux images, dealing with a 40 year old GPS standard, & trying to shoehorn functional programming into Python: Tracking vehicle location offline with a Raspberry Pi. (Part 1)
pythonscalalinuxtelematicsgpstypesfunctional programming
- Functional Programming concepts I actually like: A bit of praise for Scala (for once)
2022-06-01: Types, type classes, implicits, tagless-final, effects, and other things: Not everything in the world of functional programming is bleak and overly academic. A view on FP & scala concepts someone who loves to complain actually likes.
scalafunctional programmingoopproceduraljavapythongotypescript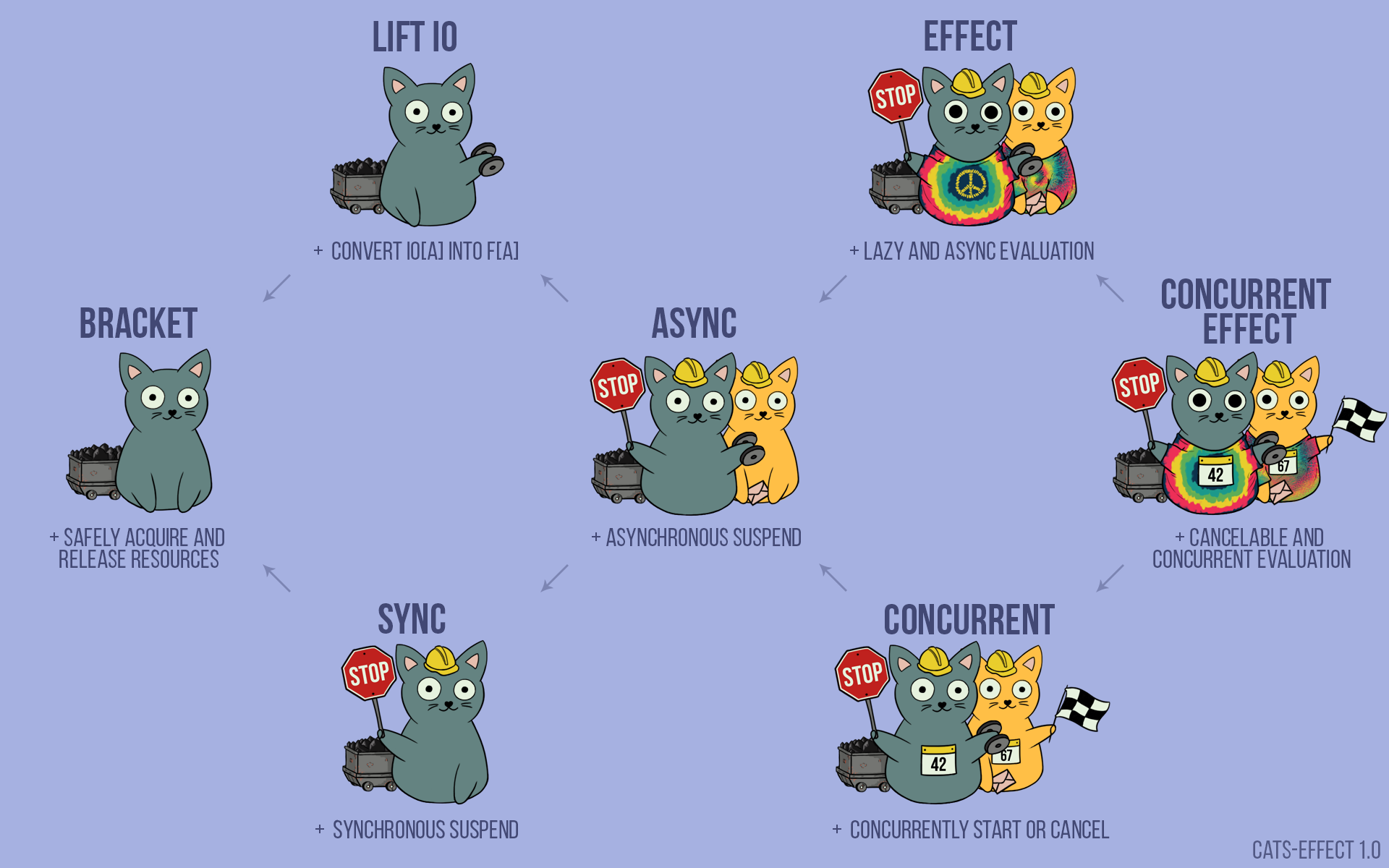
- Scala, Spark, Books, and Functional Programming: An Essay
2022-02-27: Reviewing 'Essential Scala' and 'Functional Programming Simplified', while explaining why Spark has nothing to do with Scala, and asking why learning Functional Programming is such a pain. A (maybe) productive rant (or an opinionated essay).
scalafunctional programmingoopspark
- Building a Data Lake with Spark and Iceberg at Home to over-complicate shopping for a House
2021-12-03: How I build what is essentially a self-service Data Lake at home to narrow down the search area for a new house, instead of using Zillow like a normal person, using Spark, Iceberg, and Python.
scalasparkicebergpythonsqltrinogeopandasbig datahadoophiveprestogeospatial dataanalytics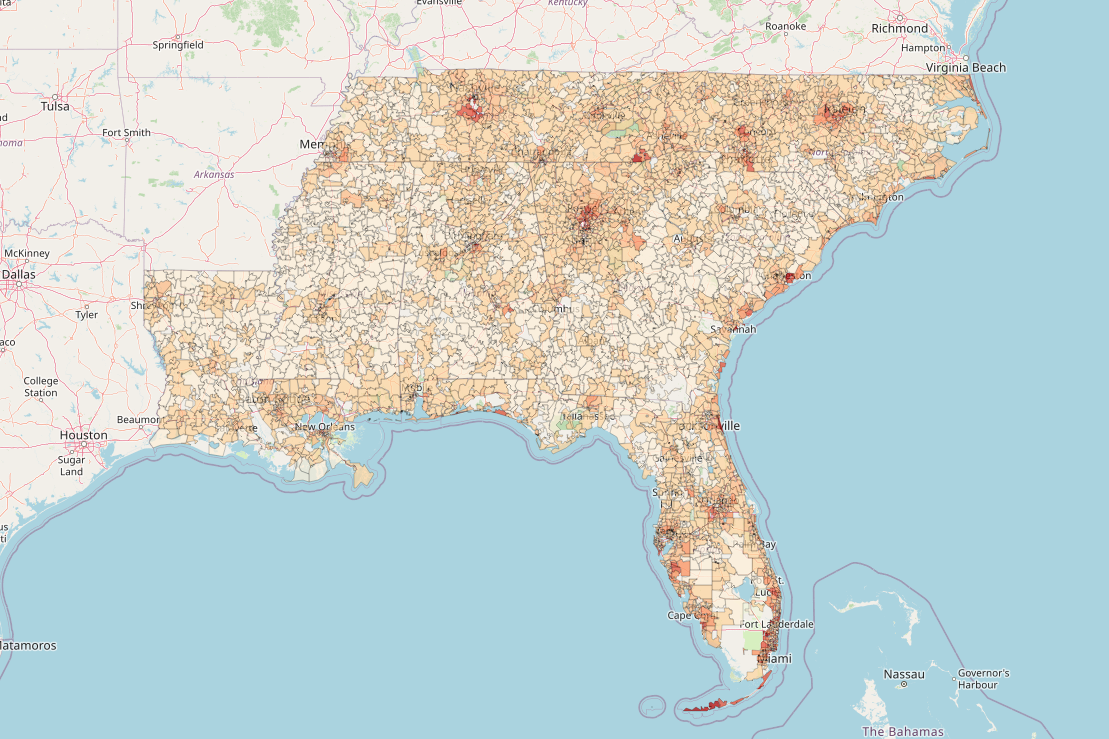
- Writing a Telegram Bot to control a Raspberry Pi from afar (to observe Guinea Pigs)
2021-08-12: A quick project to write a Telegram chat bot that can control a camera, connected to a Raspberry Pi, to take pictures of things; or: Why I refuse to trust IoT vendors and do everything myself
goraspberrymakerservercameraiotsecuritylinuxdocker
- Raspberry Pi Gardening: Monitoring a Vegetable Garden using a Raspberry Pi - Part 2: 3D Printing
2021-07-03: Part 2 of throwing Raspberry Pis at the pepper plants in my garden: On the topics of 3D printing, more bad solder jobs, I2C, SPI, Python, go, SQL, and failures in CAD.
pythongoraspberrymakeri2celectronicsspiapirestlow levelcad3d printing
- Raspberry Pi Gardening: Monitoring a Vegetable Garden using a Raspberry Pi - Part 1
2021-04-25: On how growing vegetables is more complicated than it looks, why bad soldering still works, on moving individual bits around, and what I learned about using technology where one probably does not need technology.
pythongoraspberrymakeri2celectronicsspiapirestlow level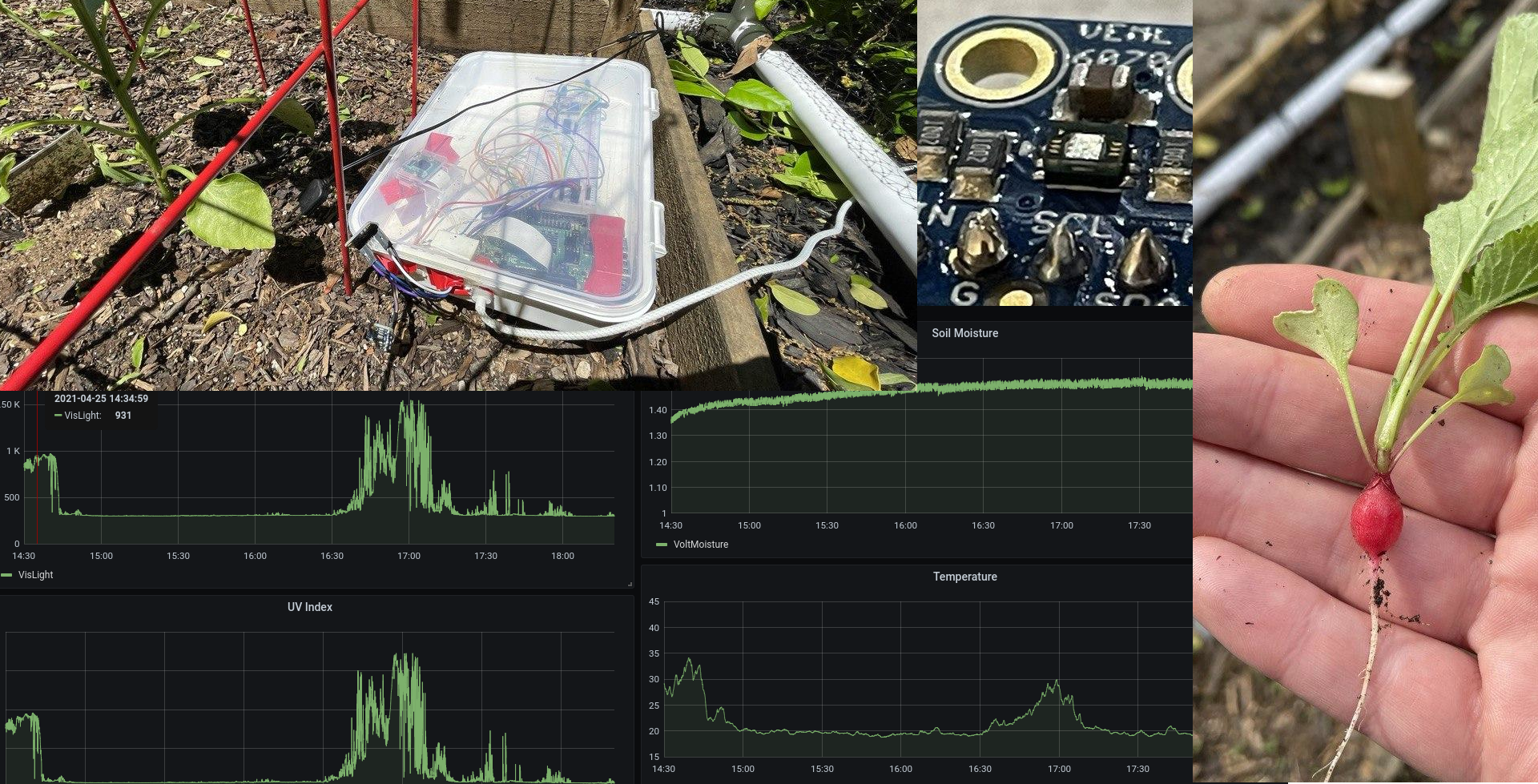
- Bad Data and Data Engineering: Dissecting Google Play Music Takeout Data using Beam, go, Python, and SQL
2021-02-28: On the joy of inheriting a rather bad dataset - dissecting ~120GB of terrible Google Takeout data to make it usable, using Dataflow/Beam, go, Python, and SQL.
data engineeringlinuxbashgopythondataflowbeambig data
- Why I use Linux
2020-12-21: One question I do get in earnest quite frequently is why I put up with running GNU/Linux distributions for development work. An attempt at a simple response.
linuxgnuprogrammingbsdmacwindows
- RE: Throw Away Code? Use go, not Python or Rust!
2020-09-26: Responding to an article on using Rust for throw away code and prototyping: Making a case for go over Rust, Python, and perl.
gorustpythonperlgolangprogrammingbenchmarkingperformancedevelopmentlinux
- A Data Engineering Perspective on Go vs. Python (Part 2 - Dataflow)
2020-07-06: In Part 2 of our comparison of Python and go from a Data Engineering perspective, we'll finally take a look at Apache Beam and Google Dataflow and how the go SDK and the Python SDK differ, what drawbacks we're dealing with, how fast it is by running extensive benchmarks, and how feasible it is to make the switch
gogolangpythondataflowbeamgoogle cloudgcpsparkbig dataprogrammingbenchmarkingperformance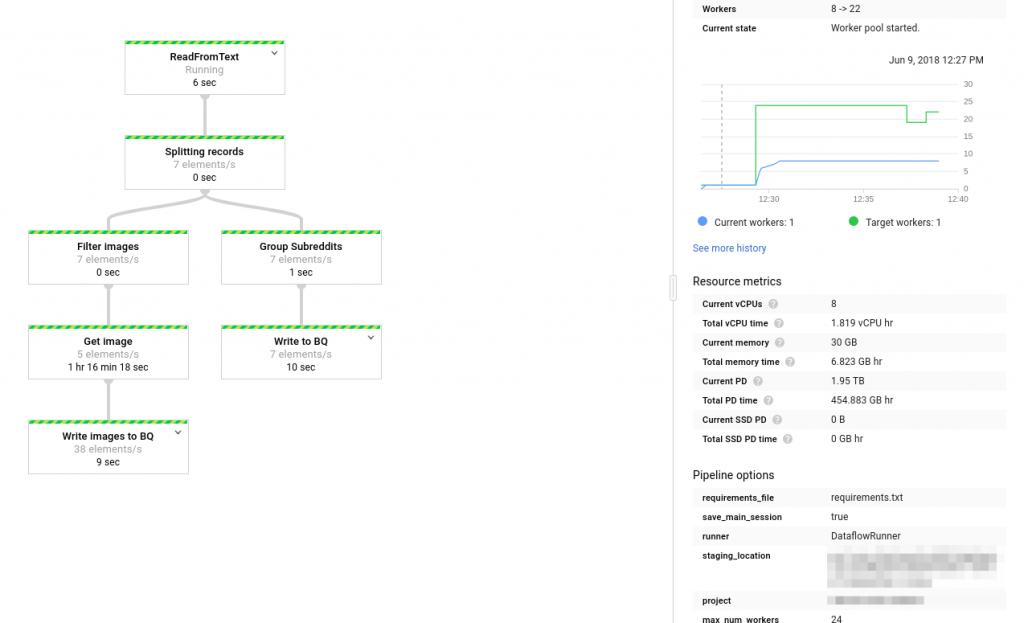
- A Data Engineering Perspective on Go vs. Python (Part 1)
2020-06-11: Exploring golang - can we ditch Python for go? And have we finally found a use case for go? Part 1 explores high-level differences between Python and go and gives specific examples on the two languages, aiming to answer the question based on Apache Beam and Google Dataflow as a real-world example.
gogolangpythondataflowbeamsparkbig dataprogramming
- Goodbye, WordPress - Hello, Hugo & nginx
2020-05-21: Ditching WordPress for a static site generator
linuxwebhugohtmlcssgoci cdgithub actionsjavascript
- How a broken memory module hid in plain sight
2020-02-25: How a broken memory module hid in plain sight – and how I blamed the Linux Kernel and two innocent hard drives
linuxkernelcnetwork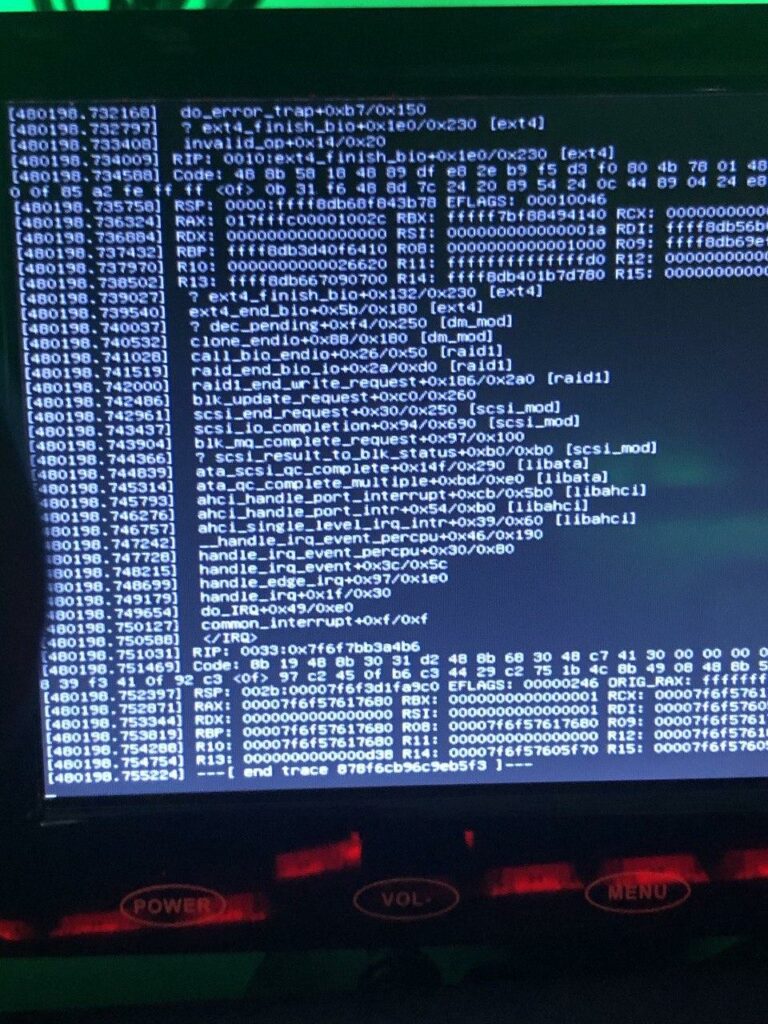
- Tensorflow on edge, or – Building a “smart” security camera with a Raspberry Pi
2019-12-09: The amount of time my outdoor cameras are being set off by light, wind, cars, or anything other than a human is insane. Overly cautious security cameras might be a feature, but an annoying one at that...
big datalinuxmachine learningmakerprogrammingpythonraspberrytensorflowvision
- How I built a (tiny) real-time Telematics application on AWS
2019-08-07: In 2017, I wrote about how to build a basic, Open Source, Hadoop-driven Telematics application (using Spark, Hive, HDFS, and Zeppelin) that can track your movements while driving, show you how your driving skills are, or how often you go over the speed limit - all without relying on 3rd party vendors processing and using that data on your behalf...
awsbashcloudiotkinesislambdalinuxprogrammingpython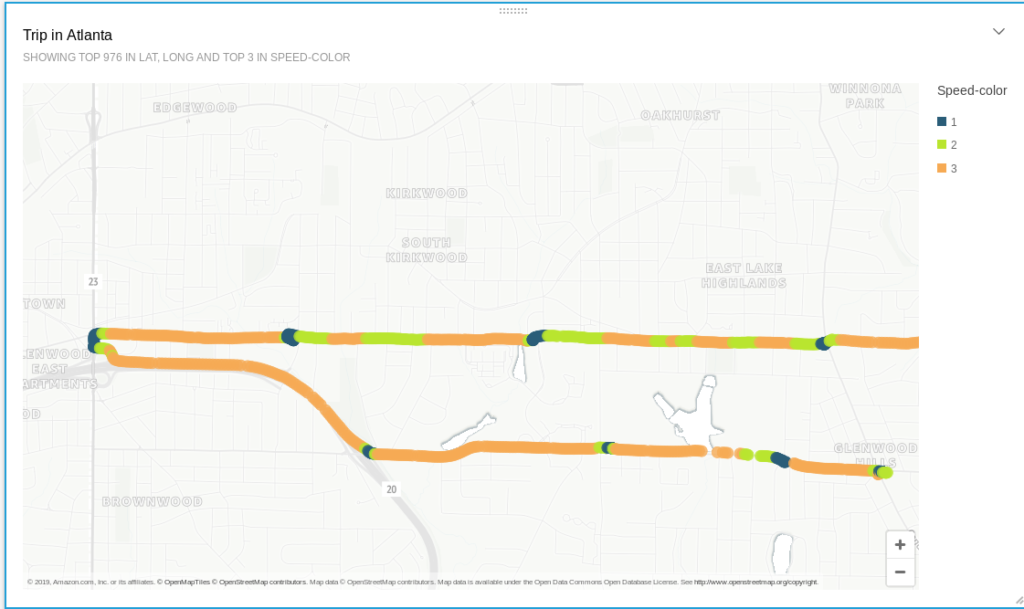
- A look at Apache Hadoop in 2019
2019-07-01: In this article, we'll take a look at whether Apache Hadoop still a viable option in 2019, with Cloud driven data processing an analytics on the rise...
awsazurebig datacloudgoogle cloudhivelinuxprogrammingspark
- Building a Home Server
2019-04-11: In this article, I’ll document my process of building a home server - or NAS - for local storage, smb drives, backups, processing, git, CD-rips, and other headless computing...
linuxbashnetworkingbig datadebiancentosencryptionluksprivacysecuritywindowsserversysadmin
- Analyzing Reddit’s Top Posts & Images With Google Cloud (Part 2 - AutoML)
2018-10-27: In the last iteration of this article we analyzed the top 100 subreddits and tried to understand what makes a reddit post successful by using Google’s Cloud ML tool set to analyze popular pictures.
analyticsautomlbig datacloudgoogle cloudgcpmachine learningprogrammingpythontensorflowvision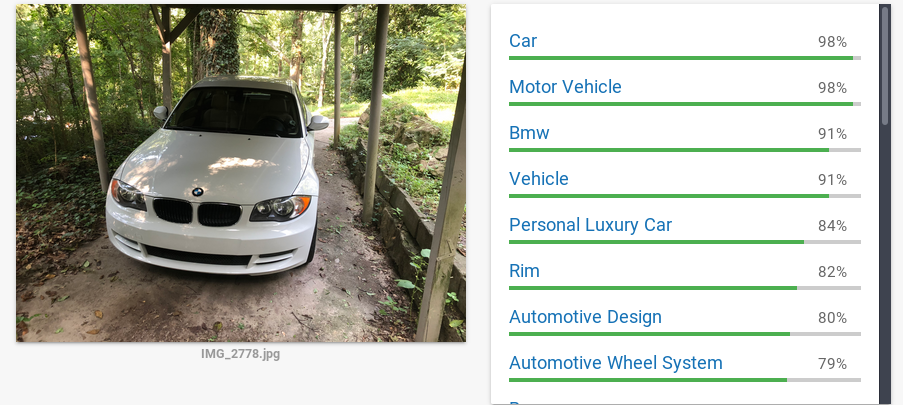
- Analyzing Reddit’s Top Posts & Images With Google Cloud (Part 1)
2018-06-12: In this article (and its successors), we will use a fully serverless Cloud solution, based on Google Cloud, to analyze the top Reddit posts of the 100 most popular subreddits. We will be looking at images, text, questions, and metadata...
analyticsautomlbig datacloudgoogle cloudgcpmachine learningprogrammingpythontensorflowvision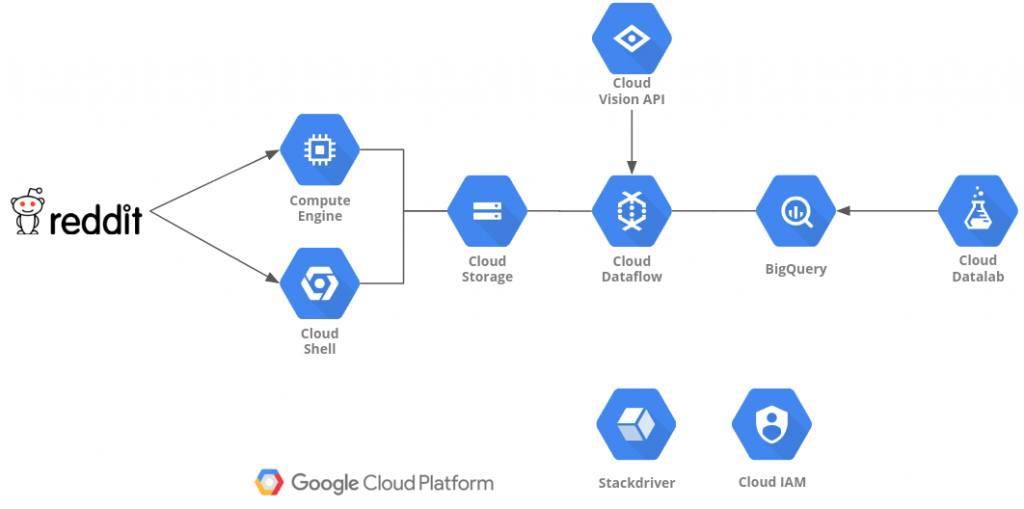
- Analyzing Twitter Location Data with Heron, Machine Learning, Google's NLP, and BigQuery
2018-03-18: In this article, we will use Heron, the distributed stream processing and analytics engine from Twitter, together with Google’s NLP toolkit, Nominatim and some Machine Learning as well as Google’s BigTable, BigQuery, and Data Studio to plot Twitter user's assumed location across the US.
analyticsbig datacloudgoogle cloudgcpmachine learningprogramminghbasenlpheronstormjava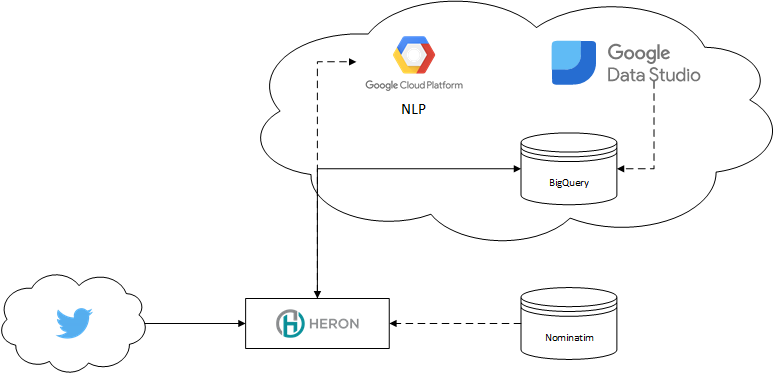
- Data Lakes: Some thoughts on Hadoop, Hive, HBase, and Spark
2017-11-04: This article will talk about how organizations can make use of the wonderful thing that is commonly referred to as “Data Lake” - what constitutes a Data Lake, how probably should (and shouldn’t) use it to gather insights and why evaluating technologies is just as important as understanding your data...
big datahbasehivesparkscalaphoenixdata lakehadoop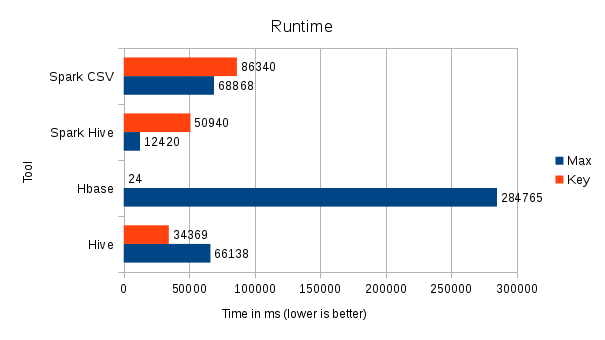
- (Tiny) Telematics with Spark and Zeppelin
2017-03-06: How I made an old Crown Victoria "smart" by using Telematics...
carconnected cartelematicshiveiossparkzeppelinhadoopscala
- Storm vs. Heron – Part 2 – Why Heron? A developer’s view
2016-12-02: This article is part 2 of an upcoming article series, Storm vs. Heron.
big dataheronsparkjavahadoopstorm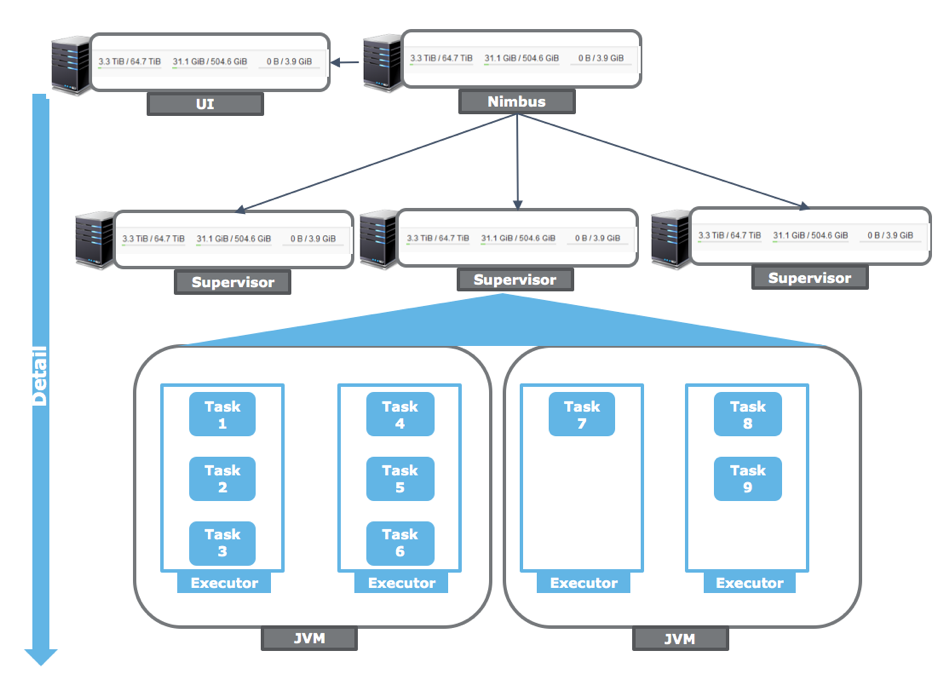
- Storm vs. Heron, Part 1: Reusing a Storm topology for Heron
2016-10-15: This article is part 1 of an upcoming article series, Storm vs. Heron.
big dataheronsparkjavahadoopstorm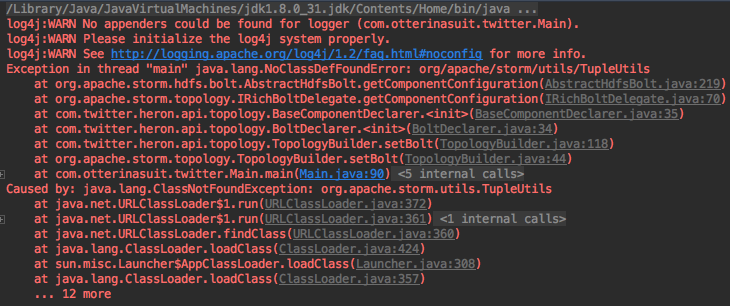
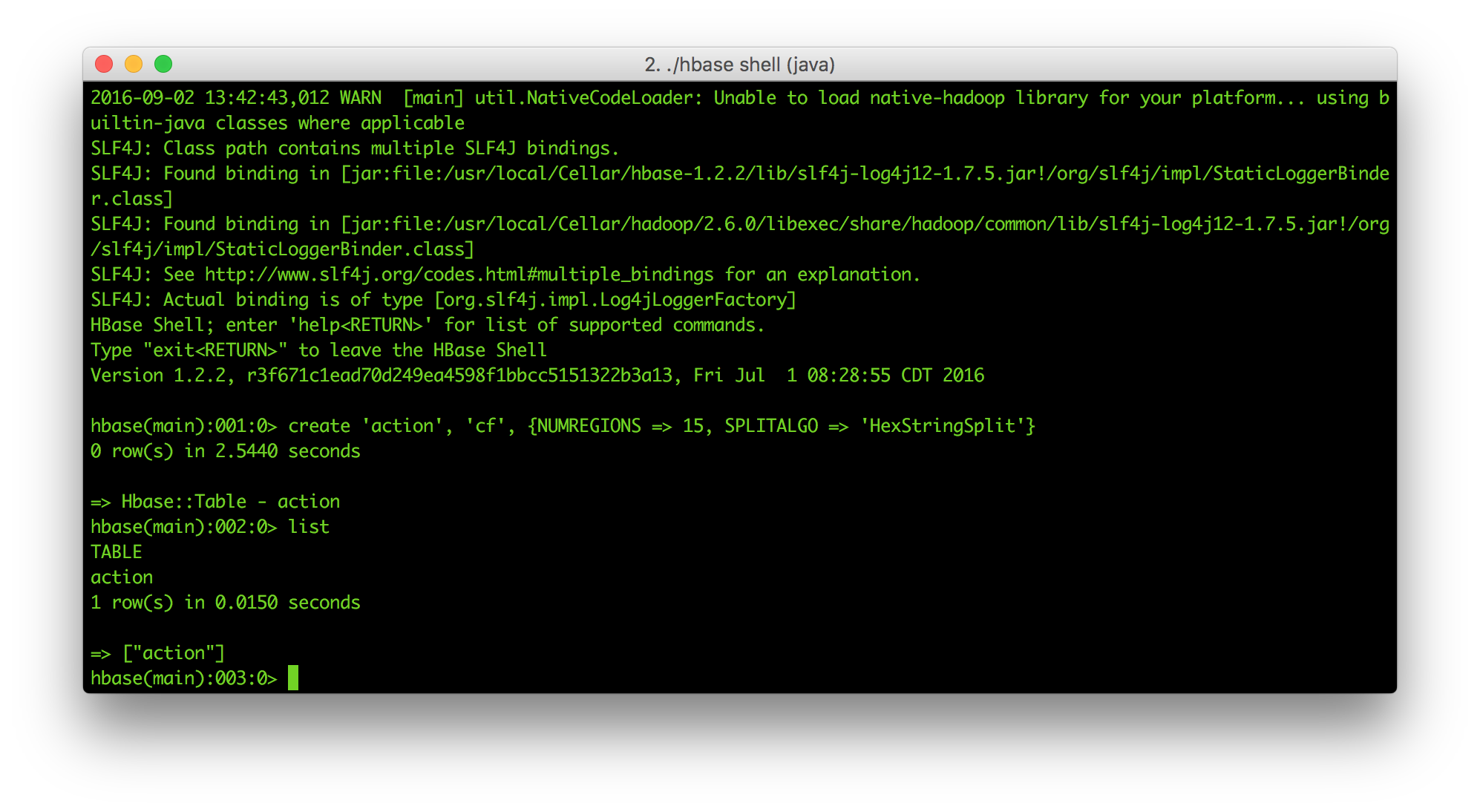
- Update an HBase table with Hive... or sed
2016-09-04: This article explains how to edit a structured number of records in HBase by combining Hive on M/R2 and sed - and how to do it properly with Hive.
hbasehivehadoop