Building something that already exist (but worse) so I don't have to think about Leetcode: Bridge Four, a simple, functional, effectful, single-leader, multi worker, distributed compute system optimized for embarrassingly parallel workloads.
➡️ Part 2: Consistency guarantees & background tasks
➡️ Part 3: Job submission, worker scaling, and leader election & consensus with Raft
Having found myself recently fun-employed in the great tech layoffs of 2023 (cue ominous thunder in the background) [1], I found myself in a bit of a conundrum: For landing a job, one needs to pass interviews. For passing interviews, one needs to jump through ridiculous hoops and, one of my favorite phrases, “grind Leetcode”.
That is associated with two problems: It is ridiculously boring, dull, and, more importantly, completely (pardon my French) f*cking useless.
The other problem was that I found myself with quite a bit of time on my hand to do stuff 9-5 that nobody needs to pay me for: I could finally read “Crafting Interpreters” by Robert Nystrom! I could learn Rust! I could deep dive into Scala 3! Or, of course, I could solve Binary Tree problems in untyped Python that have like, one, bespoke solution. And I’d have to pay for it, probably.
Now, this article originally stems from a rant against Leetcode - which I still might write - which famously tests your ability to memorize patterns, rather than good software design.
So, I’ll cut this short: Instead of doing that, I built a simple, WordCount-esque, distributed data processing system from scratch in Scala 3 w/ cats-effect. Seemed like a reasonable, way more interesting challenge.
Now, if you’re asking why: I’m in Data Engineering or, how I like to quantify these days, Data Platform Engineering. My desire to churn out copy-paste pySpark jobs is low, but my desire to build high-performance, high-throughput Data Platforms is high - DE is a specialization of SWE, so we should treat it as such.
Now, these Data Platforms tend to be built on top of existing Distributed Systems (and you, as an Engineer, need to deal with the associated challenges, which requires an understanding of how they work) - Kafka, Spark, Flink, Beam etc., and of course every database with more than one server are all distributed systems. We’ll quantify what I mean by that later, by comparing to a “distributed” REST API - hint, it’s got to do with state.
However, using those (and writing jobs for them) is one thing. Writing one - now that’s an opportunity to go into some unchartered terretory. I can assure you, I’ve learned a lot more doing that than “grinding Leetcode” (whoever came up with that phrase should consider hugging a running angle grinder, btw) could ever teach me.
Grab a coffee or something, this article turned out to be a bit on the long side. [2]
Learn more about distributed systems by building a simple one from scratch - at the end, it can do a worse version of WordCount (not as Map/Reduce, though). Emphasis on simple - we’ll go over all that’s missing and omitted in this article
Get more familiar with Scala 3 and the Typelevel ecosystem (+ the changes that Scala 3 made there, too). A side goal here is also to set up a new sbt project from scratch, with scalafmt, scalafix, and all the fixins.
Write a lot of good (or at least decent) code that isn’t bogged down by corporate necessities (such as “making money” or other such nonsense :-) ) & plan out features properly
“Distributed System” here means a system that executes a workload on multiple machines/instances in parallel, communicates via the network, shares resources, and perhaps most importantly, is responsible for its own state management. The goal here is not to build something inherently useful, but rather build out a project that uses interesting (but real-world feasible) tech to deeply explore some important concepts.
The system should behave somewhat similar to Kafka Connect, with independent connectors that span N tasks and all work on an independent set of data, albeit from the same source (rather than Spark’s approach of building out execution graphs w/ adaptive query execution and other rather advanced and, shall we say, rather involved features).
While the final job for this “Part 1” will do something like WordCount, it’s not quite WordCount - but we’ll get to that.
Noteworthy fact: While I’m quite comfortable using distributed systems and building platforms around them, I am not a Distributed Systems Engineer, i.e. I don’t spend my day building databases, processing frameworks, or HPCs. As with most things on my blog, it’s mostly a learning experience and an excuse to build something. You can, of course, always reach out via email if I’m spewing nonsense here.
The Scala 3 migration is a notorious sh*tshow that doesn’t need to hide behind the famous “Oh we’re still on Python 2” stories I’m sure we’re all familiar with. [1]
The language made changes, namely:
A revised syntax (looks like Python, not a fan)
Union types (If you have to use those, you did something wrong, if you ask me)
Introduces the given and using clauses for better implicit resolution (pretty neat, but haven’t dug into the details of how it affects scope)
Multiversal Equality - easier comparisons without equals (also pretty neat)
Extension methods, basically a better way of using implicit classes (big fan)
Native support for enums aka a more concise syntax for ADTs (big fan, too)
Metaprogramming and Macros Scala 3: See below (way above my head, but caused headaches - see below)
So, one of the goals of this project was to get more familiar with Scala 3, especially compared to Scala 2. We’ll touch upon most of these organically over the course of the article.
[1] Yes, I am aware why some of that is the way it is - doesn’t change the fact that Scala 3 is still a rarity in the real world.
Another goal for this project was for me to write more code than I usually might on a given day, but not only for the sake of writing it, but rather doing in such a way that challenges me to put my PM head on and think about features, requirements, and the implementation of those. You know, useful, albeit terribly dull stuff.
I’ve also written a lot of this as wannabe-test-driven-development, i.e. actually wrote a bunch of unit tests. I don’t believe in minimum test coverage, however, and find the code coverage %s meaningless.
Expanding on the last point, knowing what to build, what not to build, why, and when is half the battle sometimes, so I treated this a bit like I would a $CORPORATION project.
Vaguely inspired by the concept of the “Build your Own X” books, requirements are simple, but cover enough basics to be useful:
Overall
The system shall be called Bridge Four (if you’re into obscenely long fantasy books, you’ll figure the module names out)
The system takes user programs that implement a simple interface. The sample program will be a variant of WordCount
The system can process files from a distributed filesystem and operates in batch mode
There is no network discovery or configuration balancing or consistency checks; configuration files are manually propagated to the leader and each worker
The system aims for atomicity, but won’t provide guarantees (at least in the first iteration)
The system manages state in memory, i.e. we won’t externalize this to e.g. redis, which would defeat the purpose of building a distributed system with challenging state management
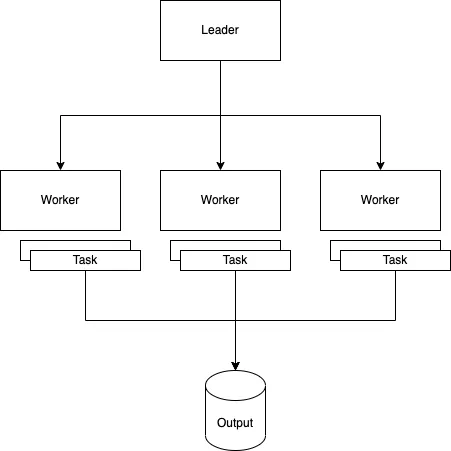
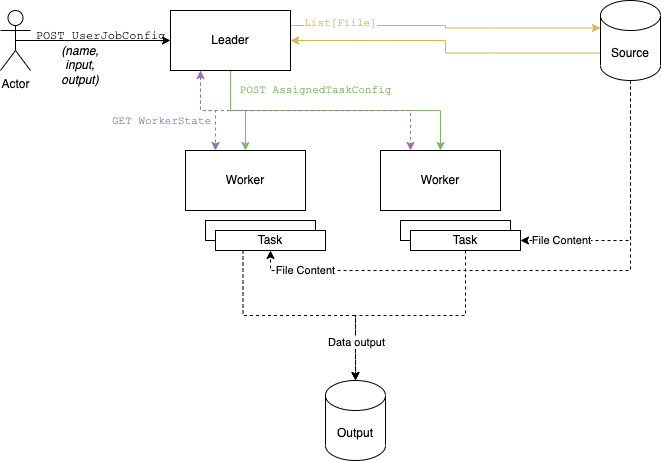
Leader
The leader module shall be called Kaladin
The system is a single leader, multiple follower system with no leader quorums or other redundancy
The leader’s main function is to assign jobs via splittable tasks to workers and ensure the completion of said jobs
One task maps to one input file, i.e. the system is dependent on decent file splits
The leader has the following subsystems:
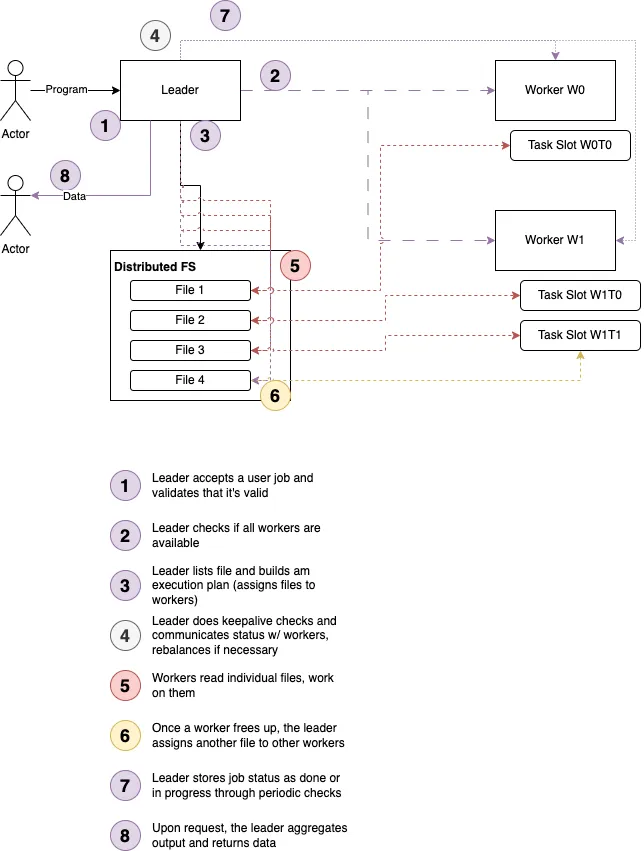
Canary / System Monitor: Checks if all workers are alive. Talks to the coordinator if one dies. Collects status data to mark completion of a job.
Coordinator / Balancer: Assigns tasks, re-assigns them if workers break
Collector: Collects a job’s output and reports it
The leader has the following interfaces:
A REST service to interact with users submitting jobs and checking status
A Background worker that automatically executes service routines
Workers
The worker module shall be called Rock (I should have named it Spren)
Workers have N static slots available for tasks. A single worker may complete the entirety or part of a job. This is the worker’s only subsystem.
Worker Slots execute their tasks on a single thread and write data directly to the target
The worker has the following interfaces:
A REST service to interact with the leader, reporting status and accepting tasks
A Background Worker that automatically executes tasks
User Jobs
User jobs will be part of the worker code base for simplicity, but will use an interface, as if they were just reading a dependency and building a jar
Implementation Details
The system will be written in Scala 3, with cats-effect
The system will be coupled to the language, i.e. has no plans to support other, non-JVM languages
Communication between leader and workers is done via JSON, not because it’s efficient, but because it’s easy
User talks to leader, user does not talk to workers
Leader talks to workers, workers do not talk to leader
The aim is to provide reasonable abstractions, within reason
I’ll further narrow this down for this “Part 1” article and define a minimum viable product, too:
It can run a bad version of WordCount across multiple workers and present output
Updating state and checking for workers and all the other canary / monitoring tasks outlined above are done via pull, i.e. the user has to ask the system to reach out to the workers to update its state, so we don’t need to build a background worker system on both leader and workers
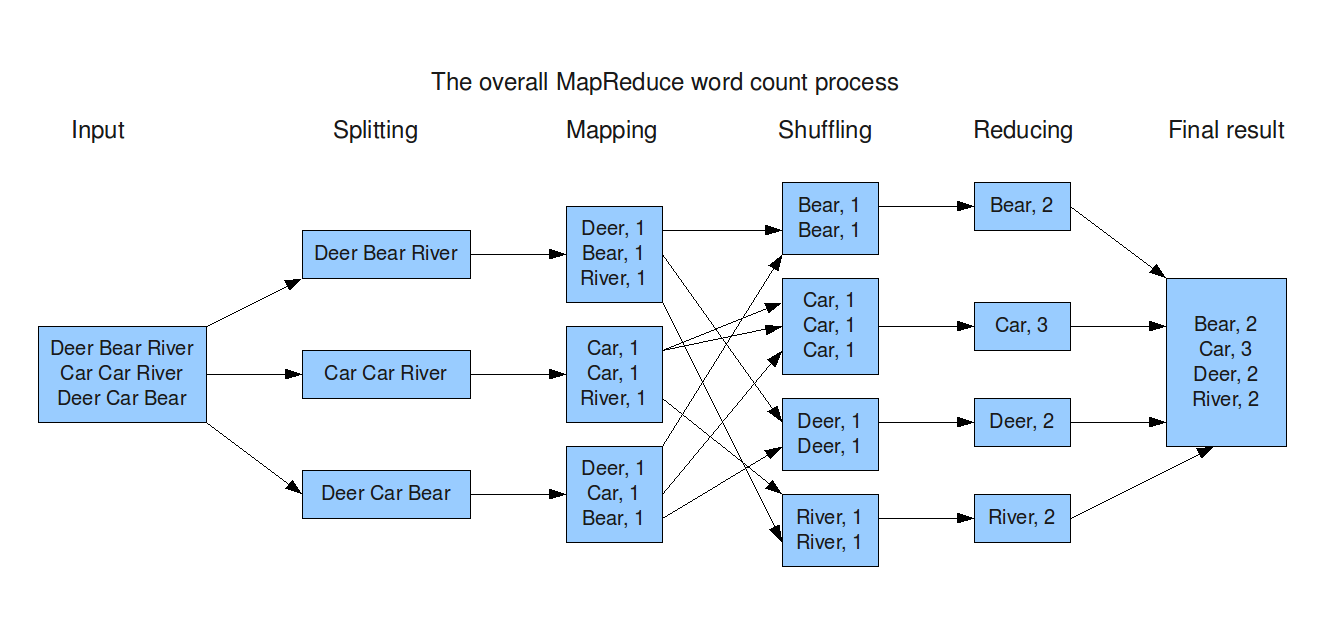
In other words, instead of the leader assigning lines of input to mappers that emit individual key-value pairs that get moved deterministically (shuffled) and then reduced to an output, our system is more naive:
It reads pre-split files (assume e.g. a Spark output with properly sized files) which can be read in parallel and write independent outputs, which the leader at the end doing the final aggregation, akin to e.g. a Sparkcollect() call that sends data to the Driver, with the idea being that each worker’s output is a fraction of the original input file. Please see below for a caveat on that in the “Breaking it” section.
That, of course, is not realistic - outside of embarrassingly parallel problems, most systems would run into a massive bottleneck at the leader’s end. [1]
However, consider a more computationally intense problem, such as distributed.net - brute forcing ciphers. With minimal adjustments - namely, a mechanism for a worker to report definitive success, which would cause the leader to ignore other worker’s output - our system here could feasibly model this, assuming we can pre-generate a set of seed files:
For a naive brute force, task A tries all combinations starting with the letter “a”, task B tries all starting with “b” and so on - the input file can be a single letter in a txt file. “Naive” is definitely the word of the hour here.
Lastly, please check the last section for a retrofit of Partitioning into Bridge Four, making this look more similar to classic Map/Reduce. Spoiler:
So, of course, our system isn’t nearly as sophisticated as even old-school Map/Reduce, but it still provides enough challenges to be interesting (and keep in mind, this is a learning-by-doing-I’m-unemployed-anyways-project):
Consistency: How do we ensure users get a consistent view on the data?
Consensus: Do we need it? If so, how?
Scalability: Say we do have do crack that MD5 password: How can we make it go faster? Does horizontal scaling work? If so, how?
Fault tolerance: What happens if a node goes offline? What happens if the leader goes offline? (Spoiler for the ladder: It implodes)
Data Replication: Instead of having a replication factor of 1, can we have a higher factor? If so, how can we support this?
Task assignment: With a single-leader system responsible for task assignment, what strategies can we employ? What are pros and cons?
Retrofitting other problems: Could this system behave like a distributed database which, instead of computing results, stores data? Or could it behave like Kafka, i.e. as a distributed message queue, where each worker maintains static data, but gets a constant influx of new data?
Note that we won’t be talking about all of those things in this article, but they’re certainly interesting problems to consider - and fun future problems to build.
This project follows roughly what I would consider “standard” functional Scala, inspired by Gabriel Volpe’s “Practical FP in Scala” (which in term is referencing this writeup by Oleg Kiselyo) albeit with some adjustments from my previous job and personal preference:
Define your DSL as tagless final encoded algebras
Define your interpreters that implement the algebras with specific typeclasses (don’t forget tests)
Define stateless programs that encapsulate your interpreters and model business logic
There’s an argument to be made that tagless final encoding (which relies on higher kinded types for the generic type F[_]) often times adds little benefit over your most highest common denominator (rather than the lowest) - say, IO.
I will add that my argument here hinges on the fact that the higher-order kinds I’m talking about here are realistically usually effects in the cats-effect sense, but the same underlying logic also applies to other type constructors, albeit to a lesser degree, since it’s easier to accurately reason about non-IO typeclasses’ behavior, since I/O (in this case, as “Input/Output” the program doesn’t control) is going to break eventually .
ThrowableMonadError[F].handleError(client.get(s"${workerCfg.uri()}/worker/status") { r =>
Sync[F.blocking(r.status match {
caseStatus.Ok=>WorkerStatus.Alive
case _ =>WorkerStatus.Dead
})
})(_ =>WorkerStatus.Dead)
}
The F[_] here is a HKT, indicating that the constructor make is polymorphic over a type constructor F and that F needs a Sync instance (in this example). By requiring an implicit Sync[F], we’re declaring that F must have a Sync instance, which we can summon implicitly and use it (or summon it inline as Sync[F].f(...)).
In this case, Syncalso implies a bunch of other typeclasses, making choosing the lowest common denominator challenging (and the Scala compiler does not help you):
In theory, this allows us to specify a different execution model later on (say, Concurrent), as long as we set the type bounds to the lowest common denominator. We could also implement this with e.g. ZIO.
Or, to put this in even simpler terms: These are generics for types in combination with general-purpose abstraction of interface and implementation, which is certainly more layers of abstractions about 99.9% of all “enterprise” code out there will ever see.
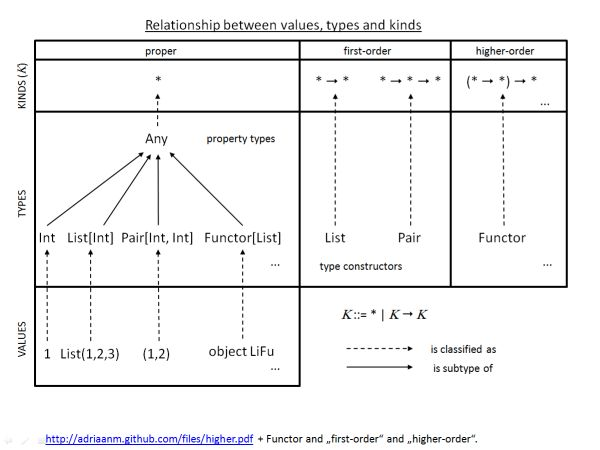
Where Int is a value type (or zero-order), List[Int is also a value type, but List[A] (the condition to constructing List[Int]) is using generics to make it a first-order type (since List cannot exist as a type, requiring one abstraction - so first-order types, as they also exist in Java, are type constructors), whereas higher-order types are repetitions of the previous steps, i.e. abstraction-over-abstraction, e.g. a Monoid.
I found this overview very helpful to visualize this:
Values, Types, and KindsL Proper, First-Order, Higher-Order.
I will note that the nomenclature here is horribly fuzzy and I tried my best to sum it up in a way that I believe to be correct - ChatGPT (which I tried to use to fact check this) is hallucinating (I’m pretty sure), and literature and sources online use different names and definitions throughout the board. I’m fairly certain “Category Theory For Programmers” doesn’t touch on the subject at all.
Back to reality: In practice, using HKTs to use Tagless Final, does makes testing easier (since individual algebras can be implemented with other effects that are within bounds) and one could argue it makes parametric reasoning easier - although I would argue, it makes parametric reasoning only possible for interpreters, not algebras, because the HKTs are simply too abstract for real-world systems to reason about.
In any case, it is a very heavy handed abstraction that takes the mantra of “write generic, extendable code” to 11.
Now, compare this to a concrete implementation with the all-powerful IO:
Given that our leader and worker will always communicate via the network outside of unit tests, using IO could be seen as a very reasonable default here (IO is easily unit-testable) and, arguably, would yield much simpler code with a lot less choices around type classes.
For this (intentionally simple) example, IO and Sync look similar, but the more complex the signatures get, the more headaches does it cause: DelayedBridgeFourJob[F[_]: Async: Temporal: Logger] drove me up the wall and I will let the readers guess why that is. Hint: The concept of implicit imports has something to do with it.
The conversation here is certainly different for a super abstract library (and one could argue, that’s what we’re doing here) vs. for the every-day applications most of us actually get paid to write: A library benefits from heavy abstractions, so it does not box the user into cat-effect’s IO monad.
However, I still have a hard time seeing the real-world benefit in most day-to-day applications. We should write code to solve problems, not to appear smart - and HKTs certainly have a habit of feeling like very complex, premature abstraction.
But no matter where you stand here, the overall technique certainly makes for more properly abstracted and modular code, and following the pattern of “a program is a collection of algebras and other programs” allow you to write your entire logic without actually writing any implementation code, which is very neat - but I think that also works with one concrete type.
As a final note, I’ve had this conversation at $FORMER_WORK months ago and we did, in fact, decide not to use HKTs for a particular project. Funnily enough, while writing this up, I found a similar piece by John A De Goes (who’s stuff is always worth a read, btw!), which raises similar concerns about premature abstraction (+ a bunch of other things I invite you to read).
If you commit to not committing, you’re stuck with the weakest F[_], which means much of the power of an effect system remains inaccessible.
One of the bigger derivations from the tagless final pattern is my use OOP to cut down on copy-paste code without being overly clever with FP (which is idiomatic Scala, for all intents and purposes). I find the more “proper” FP implementations often too hard to read, usually due to a ton of implicit imports and/or rather complex type signatures and/or composition techniques where I’m clearly to dense for (anything currying for instance maybe proper, but reads insane, if you ask me).
Because of that, you will also find OOP-inspired patterns in my code, such as protected members:
Or even implemented functions in traits, as long as they are pure.
My only rule with these non-algebra interfaces is that traits inherently define functions, not variables (as traits have no member variables), hence prefixPath is a function, but the implementation can be a val.
Lastly, I also like having descriptive, Java-style package names, but still organize them (mostly) the same way, i.e. services, programs, models, routes etc., rather than very deeply nested packages.
With all that out of the way, the rest of the article will talk about noteworthy implementations (but by no means everything). Please note that this project certainly has a “forever WIP” feel to it, which means it’s by no means complete. See above for the “MVP” scope.
I basically tried to build this MVP in three phases, not counting planning or setting up a new cats project from scratch and yelling at sbt:
First, we set the baseline and define all the abstract “things” we need, such as a BackgroundWorker or a Persistence layer. When bootstrapping a project, there is sometimes things we know must exist, so we can define them and test them in a vacuum. This is also the point where we’ll pick up some Distributed Systems conversations from earlier.
Next, we make the leader and workers talk: This includes designing interfaces, actually implementing routes (by building services), building data models, defining configurations, and testing communication. At the end of the day, the leader should be able to talk to the workers.
Lastly, we make the workers do actual work, i.e. execute real tasks, see what happens, and discuss what’s next and how one can easily break this
A Background Worker is an abstract thing that can execute arbitrary tasks in parallel and collect results. We need this for a single worker to execute N tasks, which is a multi-threading, not a distributed problem.
However, if you squint at that problem hard enough, you might realize that this is essentially the mini version (or subset) of a distributed system - just that the distribution here happens on a single machine across multiple executors (in this case, green threads, known as Fibers).
Some characteristics are remarkably similar: Both do concurrent execution (on multiple machines vs. within a process), both allow for scaling (via more machines / horizontal vs. via more threads / vertical), both have overhead cost to consider, both can use a leader or leaderless architecture (if you consider e.g. the parent process as a leader), both have challenging communication paths (across-machine vs. IPC/ITC), both have to handle failures (failing machines / network [remember, the CAP theorem is garbage] vs. failing threads), both require synchronization techniques.
Of course, this tells a very flawed story if you take a step back: Many distributed systems can solve non-trivial concurrent problems and what I brushed off as “IPC/ITC and cross-machine communication” is a lot more complicated than two threads writing to a concurrent queue, which is why many (most) systems require consensus algorithms (see below), whereas with multi-threading (or even multi-processing), we can rely on both the JVM as well as the Kernel to do a lot of heavy lifting for us.
The (IMO) biggest question when talking about distributed-vs-threaded is: Who manages state? Arguably, a bunch of REST servers behind a load balancer, where each server gets a message to work on in, say, a Round Robin fashion, is a distributed system - the system processes a request as a whole on interconnected machines. Some of the complexities apply.
However, in a cluster of REST services, each service itself is stateless, somewhat by definition. While the communication between requestor (user) and rest service via the LB is bi-directional, there is no shared state between them. Therefore, it doesn’t match the definition we used for this project.
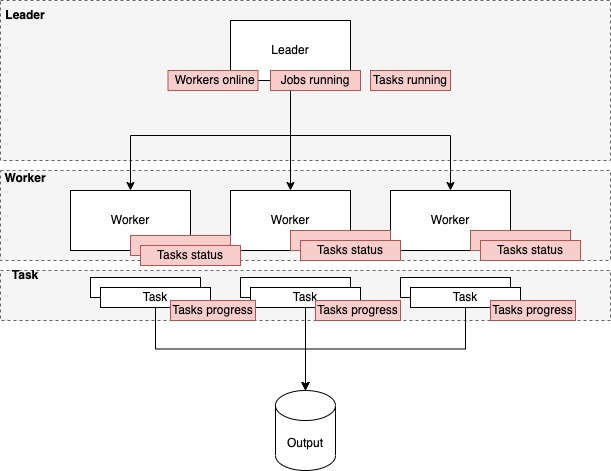
A distributed system, such as this one, does manage it’s own state, with clearly defined responsibilities:
The leader knows about which workers are online, which jobs are running (+ where), and which tasks are running (+ where). The leader has a holistic view of the system, albeit at a point in time
The workers know about the status of their own tasks: Fibers running within their own JVMs
The tasks running in the worker’s slots know only about their individual subset and their own progress
No single worker knows everything about the system, but does carry their own subset of the system (since the workers make up the system).
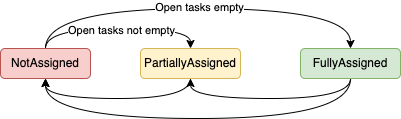
We’re making this very easy for ourselves here: Since our system is a single leader system, it has very strong consistency (albeit not technically sequential), since we have a single leader coordinating any and all interaction with the user.
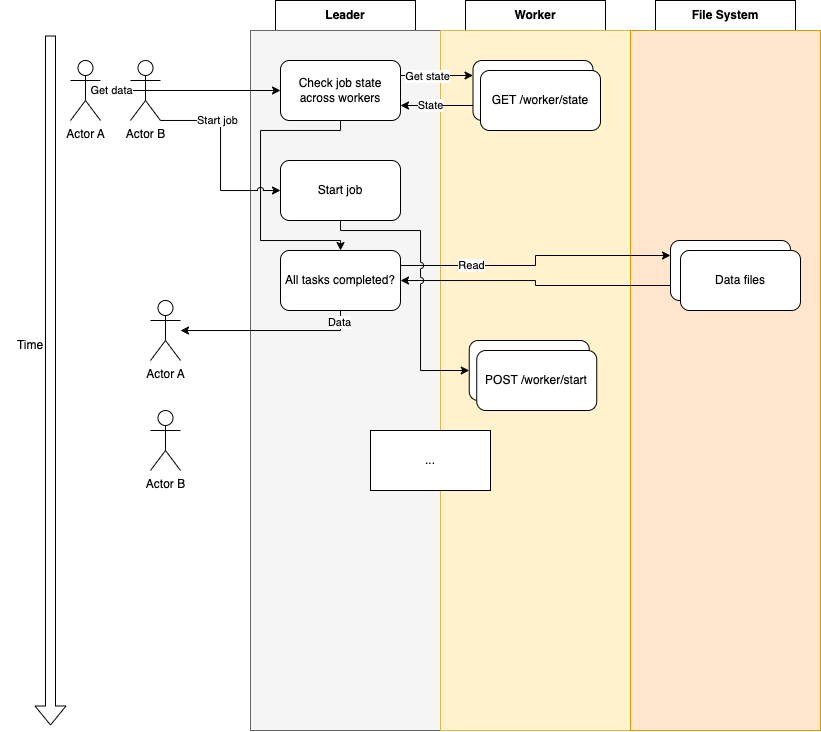
In this (simplified example) two actors, A and B, try to get data for job X (actor A), as well as start another instance/writer of job X, writing to the same data set.
In a single leader system, the access is sequential: The leader will only accept access to the job (writing to it or reading from it) from one actor at the time, meaning readers always get a consistent view of the system.
Furthermore, while workers do operate independently from one another, their output is discarded as meaningless if an entire job has not completed yet (which is, again, entirely controlled by the leader):
Consensus & Fault Tolerance, and Replicated State Machines↑
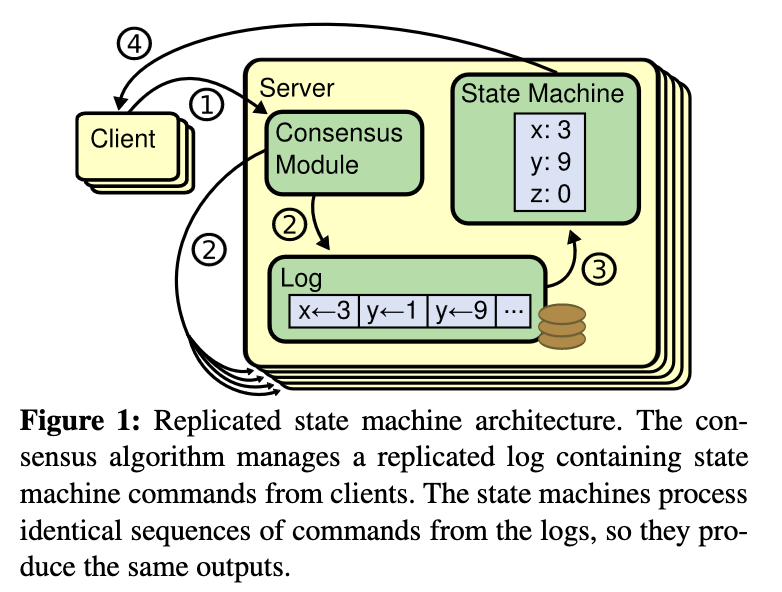
This single-leader system with “dumb” workers works differently for systems that employ something called replicated state machines, where, quote “state machines on a collection of servers compute identical copies of the same state and can continue operating even if some of the servers are down”, hence providing fault tolerance. One of the big and obvious drawbacks of a single leader system, like Bridge Four, is the lack thereof.
This diagram is taken from the Raft consensus algorithm, which also works with a single leader and then syncs all changes to said leader. The difference being, however, that workers can be promoted to leaders by employing the consensus algorithm, something that Bridge Four cannot do.
We still have multiple Finite State Machines - not replicated, but mirrored to degree, since the leader mirrors point-in-time snapshots of the worker’s state, which take precedence over the worker’s actual state.
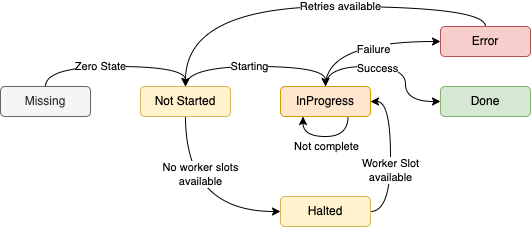
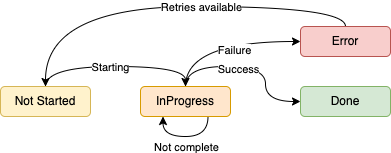
All implementations are based on simple Finite State Machine principles outlined here:
A FSM can be described as a set of relations of the form:
State(S) x Event(E) -> Actions (A), State(S')
Actions here are a little bit more involved (see the rest of the article :-) ), so we can boil this down to the following in its simplest form:
traitStateMachine[S, E] {
deftransition(initState: S, event: E):S
}
Naturally, an action could also be modeled as
traitStateMachineWithAction[S, E, A] {
deftransition(initState: S, event: E, action: (S, A) =>A): (S, A)
}
But I will admit that the implementation in Bridge Four is a bit janky at the time.
State machine improvement: The state machines are simple FSMs, but do not model transitions and actions well and rely to heavily on the JobDetails model
From the README.md
The original implementation was basically this:
deftransition(j: JobDetails):JobDetails
Which meant, you could do simple composition:
SM2.transition(SM1.transition(jd))
But that, of course, is very hard to reason about. The current implementation stands somewhere in the middle, still making heavy use of the JobDetails model.
For the record, I believe the de-facto reference implementation here exists in Akka, but I’m not going to start pulling that dependency in.
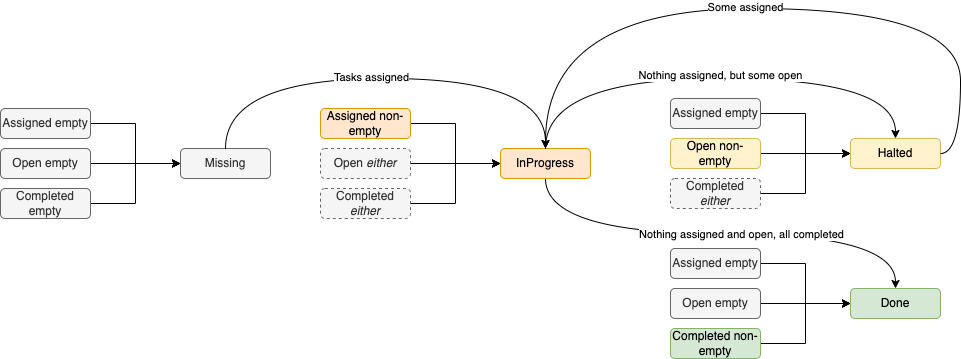
The task execution is based on a subset of the same ADT. However, a task can never be on “Hold” or “Missing” - it either exists and runs somewhere or doesn’t.
One thing to note, while a task (in the distributed job sense), a BackgroundWorker fiber can be absolutely missing if the leader somehow passes an invalid ID.
That, however, isn’t truly a state, since a task gets constructed by the leader - meaning, while calling GET http://{{rockServer}}:{{rockPort}}/task/status/$INVALID_IDwill return a “Missing” result, that doesn’t model part of the lifecycle of a task, which is what we care about in this section.
defget(key: Long):F[Option[FiberContainer[F, A, M]]]
defgetResult(key: Long):F[BackgroundWorkerResult[F, A, M]]
defprobeResult(key: Long, timeout: FiniteDuration):F[BackgroundWorkerResult[F, A, M]]
}
// ...
caseclassFiberContainer[F[_], A, M](fib: Fiber[F, Throwable, A], meta: Option[M])
caseclassBackgroundWorkerResult[F[_], A, M](res: Either[ExecutionStatus, A], meta: Option[M])
def start(key: Long, f: F[A], meta: Option[M] = None): F[ExecutionStatus] starts a function that returns F[A] and, optionally, allows for the provision of metadata of type M.
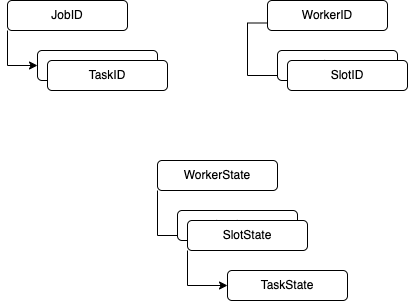
The key is any Long (a generic type K made this even more unwieldy), which in case of the worker implementation is the SlotTaskIdTuple (basically all IDs we need to match a slot to a job).
The metadata is tremendously useful when probing for results, i.e. getting metadata about a task when a task hasn’t completed yet.
In a world without metadata, get (or probe) would return a Option[Fiber[F, Throwable, A]] (or an Either[ExecutionStatus, Fiber[...]]), which means we would need a separate system to keep track of what exists within the BackgroundWorker. For instance, if we use the BackgroundWorker to start a 2 tasks from 2 jobs on a worker (and hence, in 2 slots), how do we know which job the task in e.g. slot 0 belongs to?
At the same time, this also throws a bit of a wrench into the state machine definition from above once we need to use this for the TaskExecutor (see below):
With the (generic) BackgroundWorker being responsible for returning an ExecutionStatustoo, the pattern match for the TaskExecutionStateMachine is far from ideal, since it doesn’t accurately model a transition anymore, since that is a property of the BackgroundWorker we’re discussing here:
However, this boils down to a classical issue of “too little or too much abstraction” at point X - this can be cleaned up, but is an almost impossible task to get right from the get go if we want to get anything functional done.
Also, note that this algebra doesn’t specify a capacity: That is a function of an implementation, which we’ll skip for now, since we need to talk about a prerequisite fist.
And that would be persistence. Since we also talked extensively about state in the previous section, let’s define a way to store state (and, by proxy, make our generic worker able to store tasks and results):
sealedtraitPersistence[F[_], K, V] {
defput(key: K, value: V):F[Option[V]]
defget(key: K):F[Option[V]]
defdel(key: K):F[Option[V]]
}
This is very similar to e.g. a Map implementation: You get put, get, and delete.
A simple implementation is worth briefly discussing at this point:
The eagle-eyed among you will have noticed the use of MapRef, rather than a regular data structure, which provides a Ref - a concurrent mutable reference - around a map.
If we were to use a, say, ConcurrentTrieMap without a Ref, the entire map would need to be re-written on each access, not to mention the need for rolling our own concurrency primitives. This makes this a lot easier, but makes searching near impossible, at least without another locking mechanism + persistence store.
Bridge Four solves this by assigning slot IDs sequentially starting at 0, meaning you can scan all slots if you know about the worker’s slot capacity.
Another form of this is a Counter that stores key-value pairs with an associated count:
sealedtraitCounter[F[_], K] {
definc(key: K):F[Unit]
defdec(key: K):F[Unit]
defset(key: K, value: Long):F[Unit]
defget(key: K):F[Long]
}
We don’t necessarily need one (I thought we did at one point, so I built it - once with MapRef, once with Ref + Mutex), but it’s fun talking about it.
The implementation here looks similar, but has much harsher concurrency penalties (in theory): In a regular MapRef, if two threads write to the same key, one will ultimately prevail, which is generally expected behavior. The previous value is generally discarded.
For a counter, race conditions can be a bigger problem, since the current view of the data always depends on the previous state of the data.
If Threads 1 and 2 both increment a counter and Thread 3 decrements it, the result will always be the same, since operations are all commutative:
However, if you skip an operation (or call a set() in the middle of it), the result is obviously not the same!
Now, for a multi-threaded problem, this is on the edge of “testing library code in unit tests” (which we’ll do in a second), but consider for just a moment that we’d have the same counter across the entire cluster. How does that change things?
At that point, we’d have to talk about delivery guarantees (which is a subset of consistency, arguably), which I will refrain from doing now - but keep in mind that these are the types of issues that are similar in multi-threaded problems, but certainly not the same as the same problem in distributed workloads.
For the record, I’m not against “testing library functionality” for concurrency stuff, just because concurrency is hard and easy to mess up, so it doesn’t hurt:
A TaskExecutor is ultimately the Worker service that reports the internal state of the individual workers back to the leader. We’ll talk about communication in the next section.
Thes resulting program requires a specific BackgroundWorker that can store TaskState + metadata about slot + task ids.:
Those do what we discussed: Split a job, plan out assignment to workers, and start tasks on workers, as well as model most other leader functionalities, namely getting result.
Note that this explicitly does not handle state as part of the algebra, but does as part of the resulting program:
At this point, we have a skeleton project (quite literally with a IO.println("HelloWorld") in there), but we’ve already established that our leader-to-worker communication is going to be done via REST.
Remember our rules:
The User talks to leader, user does not talk to workers
The Leader talks to workers, workers do not talk to the leader
With that knowledge - and the general understanding that we need to start jobs and assign them - we can build routes:
Defining the routes beforehand helps us to understand and check the flow of the application and helps us structure our code:
Component
Method
Route
Call
Payload
Returns
Description
Implemented
Kaladin
POST
/
start
JobConfig
JobDetails
Starts a job
X
Kaladin
GET
/
list / $JobId
-
JobDetails
Lists a single job
Kaladin
GET
/
list
-
list[JobDetails]
Lists all jobs
Kaladin
GET
/
status / $JobID
-
ExecutionStatus
Gets the result of a job, as Status
X
Kaladin
GET
/
refresh / $JobID
-
ExecutionStatus
Gets the result of a job and starts more teasks, if necessary, as Status. Stop-gap until this is automated
X
Kaladin
GET
/
data / $JobID
-
Either[ExecutionStatus,JSON]
Gets data, if its available. Like a Spark.collect() - moves data from workers to leader
X
Kaladin
GET
/
cluster
-
Map[WorkerId, WorkerStatus]
List cluster status
X
Rock
GET
/worker
state
-
-
200 OK for health
X
Rock
GET
/worker
status
-
WorkerState
Details on slots + tasks
X
Rock
GET
/task
status / $TaskId
-
ExecutionStatus
Gets the status of a task
Rock
POST
/task
start
TaskConfig
ExecutionStatus
Starts a tasks as a member of a job
X
Rock
PUT
/task
stop / $TaskId
-
ExecutionStatus
Stops a task
I won’t go over each and every route here, but this overview should give us an idea on what to build. It is also useful for PM to track the implementation status of each route, since realistically, each route would be its own ticket.
http4s is the HTTP framework of choice. Here’s a great talk about it. In a nutshell:
HTTP applications are just a Kleisli function from a streaming request to a polymorphic effect of a streaming response
Yeah. mmhm. I know some of these words!
Okay, I stole this from the talk, but http4s really is a functional HTTP library that benefits greatly from FP.
The general idea is: A HTTP server is a function of Request => Response, but since it’s also effectful and not all routes always exist, it boils down to a Request => OptionT[F, Response] (or Request => F[Option[Resonse], with F being the effect). If we apply another Monad Transformer (to make two different Monads compose, in this case with a function) to that, we get Kleisli[Option[T, *], Request, Response], leading us to the type alias in the actual library:
Whereas without that, we’d have a bunch of repeated match and flatMap operations across both the IO and the Options, which is fine for 2 functions, but not for large HTTP servers w/ a bunch of middleware.
In practice, it looks something like this:
valservice=HttpRoutes.of[IO] {
case _ =>
IO(Response(Status.Ok))
}.orNotFound
And can do a lot of neat things: Composable routes & middlewares, easy to test, reasonable encoding and decoding support, and very… strict… adherence to the HTTP standard. Works great with circe, cats-retry etc.
Before we get to building the actual routes, let’s talk about defining models. I won’t go over all models, but some noteworthy ones used for user-to-leader and leader-to-workers communication. [1]
[1] I’m pretty unhappy with this model and will probably simplify it in the future - it has too many independent sub-types and is generally over-abstracted, which doesn’t help readability.
On thing worth mentioning here is that in large systems, ID collisions are a huge problem that is non-trivial to solve - here, the use of Int isn’t ideal, but it did make testing easier (rather than copying 128bit UUIDs).
The interpreter for the IdMaker[F[_], A] algebra is literally called NaiveUUIDMaker, which cuts down pseudo-random UUUIDs to 32bits, whereas the one used in the unit tests always returns sequential number starting from 100.
This tells the leader about the state of an individual worker. A lack of a response (w/ retries) constitutes a dead worker.
This is the definitive source of truth for the leader to figure out what’s going on on the worker, in one single operation. The fewer distinct operations we have, the easier it is to add atomicity support later.
Scala 2 had a bunch of libraries that worked together to use compiler macros to derive type classes instances, namely via derevo and its modules for e.g. circe or pureconfig:
@derive(encoder, decoder, pureconfigReader)
caseclassSlotState(
id: SlotId,
workerId: WorkerId,
available: Boolean,
task: Option[TaskState]
)
deffoo[F[_], A:Encoder](x: A):F[Unit] =???
This was a really easy way to build domain models that could be shared across e.g. http4s and pureconfig (or any DSL). Importing them put e.g. an EntityEncoder[F, SlotState] into implicit scope. Sometimes, you’d hand-roll more complex serializers in the companion object, albeit rarely.
One of the things that made it easy was the fact that it properly abstracted the wild world of compiler macros from me, your average idiot (tm). Use the annotation, pull in the right implicit scope, do something useful.
Well, Scala 3 now has the derives keyword, as I’ve called out earlier:
caseclassThing() derivesEncoder.AsObject
Which, on paper, is great! Unfortunately, years after it’s release, it still causes 2 main issues:
The compiler doesn’t give the same useful, abstracted error messages than e.g. derevo does, forcing me to go down a rabbit hole (bear with me, I’ll take you with me)
Library support is often not needed anymore, but the docs are helplessly outdated, and, unless you’re a total Scala geek, “just read the type signature, bro” is really not helpful
Easy, it’s a chicken-and-egg problem, and derevo tells us as much:
Could not find io.circe.Encoder instance forList[com.chollinger.Stuff]
@derive(encoder, decoder, pureconfigReader)
Scala 3, however, will tell you this:
// Maximal number of successive inlines (32) exceeded,
// Maybe this is caused by a recursive inline method?
// You can use -Xmax-inlines to change the limit.
Now, what in all that’s holy is a successive inline, what does it have to do with my serializers, and why do I care?
Well, a function is marked as inline, it tells the compiler to substitute the method body directly at the call site during compilation. Straight from the docs:
Inlining of complex code is potentially expensive if overused (meaning slower compile times) so we should be careful to limit how many times derived is called for the same type. For example, when computing an instance for a sum type, it may be necessary to call derived recursively to compute an instance for a one of its child cases. That child case may in turn be a product type, that declares a field referring back to the parent sum type. To compute the instance for this field, we should not call derived recursively, but instead summon from the context. Typically the found given instance will be the root given instance that initially called derived.
In this case, because we have a mutually dependent derivation, the compiler gives up inlining anything after 32 attempts, throwing that super-not-user-friendly error at me.
While it’s great that the language itself could replace a bunch of libraries - on paper - it really soured more than one morning, since I was forced to actually dig into the language docs to solve issues which can already be annoying with a much more mature ecosystem of libraries (which is ironic).
In other words, I should not need to read parts of a language spec to do something so trivial as serializing a bunch of domain models.
This is especially helpful if you’re dealing with constructors that return an F[ServiceImpl], which happens of the construction is dependent on an effect.
You may also have spotted InMemoryPersistence, which indoes means that a dead leader takes all state with it.
You may have noticed we’ve barely talked about what constitutes a job, and that was intentional: The complexity here is not to re-write WordCount, the complexity here is around making a distributed system that is halfway-well designed (or, at least, is aware of its limitations) that can do any distributed task, and even if that’s just writing “Hello World” and having a leader that’s aware of what “Hello World” means.
The way this should work is the user should submit a jar (or at least a package name as String), with bespoke config options, and the system should execute it.
The way it does work is by having a summoner - def make[F[_]: Async: Temporal: Logger](): JobCreator[F] = (cfg: AssignedTaskConfig) - that simply runs the run: F[Unit] method on each worker (with, if the job is implemented correctly, reads AssignedTaskConfig.input of type FilePath, which is a String alias) and writes to outputFile(): String.
If you’ve been paying attention, you will also have realized the complete lack of abstraction from an actual file system (this basically assumes you’re on a UNIX-like and have something like NFS at the worker nodes available).
I am aware that this is hot garbage , thank you very much, but this was one of those points where I had to take a step back and not also build a good job interface, but rather focus on the system as a whole. This can all be replaced later, as the coupling is pretty loose.
But, for completeness’ sake, here’s the (placeholder) interface I’ve been using:
traitBridgeFourJob[F[_]] {
// this is a simple workaround to map code in this repo (BridgeFourJobs) to a Job
defjobClass:JobClass
/** Each job must work on exactly one file and write to one directory
*
* TODO: this limitations are for simple implementations and somewhat arbitrary
The same logic also applies to Leader jobs, which are the equivalent to collect() calls sending data to the driver in Spark, but with the difference being that the worker doesn’t send data - the leader receives it, once its state machine has marked a job as Done:
// TODO: See all the other "TODOs" in this file (there are 8)
// - this is a placeholder
/** Runs on leader. Reads each input file and returns a
result as String, because of the sh*tty way we construct
* these tasks. Once the system accepts JARs, this all
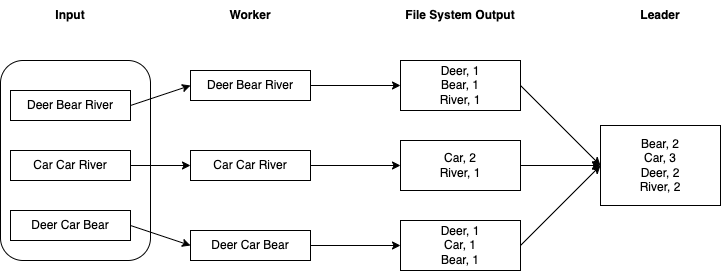
Let’s make the cluster do some work: The same job as above will simply run sh*tty WordCount on a large file, provided it has been pre-split beforehand. Again, manufactured example, but assume you’re processing the output of a different system and have a bunch of properly-sized files available.
First, we need some data: We’ll use “War and Peace” by Leo Tolstoy, since it’s long and in the public domain. We’ll create three files, each triggering a task, meaning we get five tasks on 2 workers with 2 slots each.
Once the job starts, the leader reports that it has accepted the job and managed to partially assign 4/5 tasks to workers (we only have 2x2 slots, remember?):
Those counts aren’t entirely correct, because it’s sh*tty WordCount and special characters are part of words, leading to gems such as "‘King’?”": 1,. But, again, that’s not the point - it works to do the task!
Unhappy path: Nuke workers from orbit during execution↑
Here’s where we break things and explore how well our basic fault tolerance works.
This will happen in perpetuity, since we do not have workers in the cluster, as the cluster status reports:
{
"0": {
"type": "Dead"
},
"1": {
"type": "Dead"
}
}
We can’t get data, since all we get is
{
"type": "Halted"
}
Which, as we recall from the state machine exercise, means the job (and all tasks) are in limbo (since we have no workers). We can confirm that by looking at the job details:
Because the leader now manages that data and scope, feeding off a cached copy of the data - it doesn’t need to ask the workers to provide data to it (which is different than say a Sparkcollect(), which I’ve used as a comparison before).
While this isn’t nearly the same fault tolerance as self-healing system with consensus algorithms can provide (where we can replace the leader), it’s still somewhat fault tolerant.
Now, if you made it this far (or skipped ahead), you might be skeptical: Is this really a “distributed system” in the traditional sense? But what about $THING we didn’t do?
Well, I’ve tried to touch upon most of the important Distributed Systems components, challenges, and (probably most importantly) the tradeoffs we made here when we decided not to support a characteristic or feature, where I simply decided that it’s “good enough for now”.
Nevertheless, allow me to look ahead into some (theoretical, maybe real) next steps for this system.
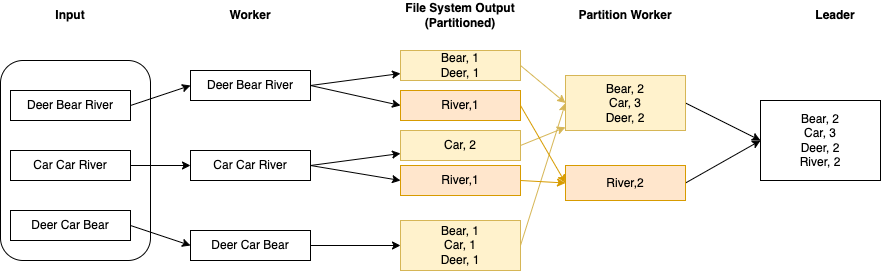
I touched upon this in the WordCount vs sh*tty WordCount example, but as a reminder, Map/Reduce and other distributed frameworks (Kafka partitions or Spark stages) assign keyed messages deterministically to workers, where our leader assignment process is greedy (fills up a worker until moving to the next one) and not deterministic, i.e. agnostic to the underlying file.
Those were decisions made for simplicity, but retrofitting some of this is certainly not out of the question, since that’s all done by this algebra:
Which looks a lot closer to Map/Reduce, with the big difference being that the partitioned output would be re-assigned to another set of workers by the leader.
Total Order Broadcast s a communication protocol to ensure that messages are delivered to all participants in the same order. It guarantees that every worker in the system receives the same sequence of messages, regardless of the order in which they were sent or network blips.
I’m calling it out for the sake of having it called out: Message ordering is a big rabbit hole which currently isn’t relevant, but could be if we were to do the WordCountV2 implementation from earlier.
Transactions, Atomic Operations, and 2 Phase Commits↑
Two-Phase Commit (2PC) is a distributed protocol used to achieve atomicity and consistency in distributed transactions across multiple participating nodes or databases. It ensures that all participating nodes either commit or abort a transaction in a coordinated manner, thereby maintaining data integrity.
Another one worth considering: How can we ensure our operations are atomic? While we’re somewhat close - remember, one leader - there are still a lot of failure scenarios in which we would break that guarantee.
Partitioning: File assignment is greedy and not optimal
Worker Stages: Jobs start and complete, the leader only checks their state, not intermediate stages (i.e., we can’t build a shuffle stage like Map/Reduce right now)
A sane job interface and a way to provide jars - the BridgeFourJob trait + an ADT is pretty dumb and nothing
but a stop gap. See the article for tdetails
Global leader locks: The BackgroundWorker is concurrency-safe, but you can start two jobs that work on the same
data, causing races - the leader job controller uses a simple Mutex[F] to compensate
Atomic operations / 2 Phase Commits
Consensus: Leader is a Single Point of Failure
Consistency guarantees: The single-leader natures makes it almost sequentially consistent, but I cannot provide
guarantees
State machine improvement: The state machines are simple FSMs, but do not model transitions and actions well and rely to heavily on the JobDetails model
I’ve been very heavy handed with Sync[F].blocking, which often isn’t the correct effect
File System Abstraction: This assumes a UNIX-like + something like NFS to be available, which isn’t ideal and has
it’s
own locking problems
When “grinding” Leetcode, I found myself drifting off, my body actively rebelling against the notion of wasting time in the time wasting machine, for the purpose of “let’s pretend we’re all cool FAANG people”.
This project, on the other hand, was actually fun! Sh*tton of work, yes, but actually fun!
While the cynics among you might scoff and say “you just built a REST API, what’s the big deal” - at least I got to play with Scala 3 a bunch then.
Don’t get me wrong, I disagree - you have about ~10,000 words above outlining why I think this is a bona fide distributed compute engine, albeit one that skips a lot of the really complicated topics for now.
But, I cannot stress this enough: The thing actually works. You can try it if you want. :-)