Introduction↑
I self host everything but email. I wrote about this here, here, or here.
As a summary, at home, I run a 3 node Proxmox cluster with several services, powering a home network with Mikrotik router, Mikrotik switches, and UniFi WiFi, as well as an external VPS.
This article is about two things: Why I still bother and what it has recently taught me. Think of it as a brief retrospective and an encouragement for readers to go down the same rabbit hole.
heimdall.lan.
(Credit: Background from HBO promo material)
My Services↑
I self host:
PiHoleas DNS resolver (redundant)- RouterOS (probably stretching the “self hosting” a bit, but it does DHCP, VLANs, Firewalls, DNS routing and such)
UniFi controlleras a WiFi controllerheimdallas a landing pageTrueNASas a file server (redundant)giteaas a local git serverwiki.jsfor general knowledge storingVS Codeas a browser based editor- A
Ubuntudev VM for general code shenanigans (Debian otherwise) mariadbfor database needsredisfor forgetful database needsInfluxDBfor specific database needs (aka “projects I mean to get back into”)LibreNMSas a network manager and monitoring suiteCalibre Webfor E-Books and papersKomgafor comicsJellyfinfor general mediaHomebridgefor internet of sh*t (tm) devices I don’t need
In addition to that, I also have had an external VPS for 10+ years, which hosts:
nginxfor my website and this blogfirefoxsync-rs, Firefox sync to sync Firefox synchronously (the newrustversion, too!)Nextcloudto host files, calendar, and contacts
As you can imagine, this can be quite a bit of work. I, despite common sentiment, also have a live outside of computers. Matter of fact, I’d rather spend my weekends outside (provided it’s not 90 degrees). Which sometimes conflicts with hosting all this.

For those unfamiliar: Outdoors! (Sample image from our garden).
(Credit: by me)
So… why bother?
Why I self host↑
Most of this article is not purely about that question, but I dislike clickbait, so I’ll actually answer the question from the title: Two reasons.
First of all, I like to be independent - or at least, as much as I can. Same reason we have backup power, why I know how to bake bread, preserve food, and generally LARP as a grandmother desperate to feed her 12 grandchildren until they are no longer capable of self propelled movement. It makes me reasonably independent of whatever evil scheme your local $MEGA_CORP is up to these days (hint: it’s probably a subscription).
It’s basically the Linux and Firefox argument - competition is good, and freedom is too.
If that’s too abstract for you, and what this article is really about, is the fact that it teaches you a lot and that is a truth I hold to be self-evident: Learning things is good & useful.
Turns out, forcing yourself to either do something you don’t do every day, or to get better at something you do occasionally, or to simply learn something that sounds fun makes you better at it. Wild concept, I know.
In my real job, I’m not a sysadmin, but actually a software engineer. I work on large, distributed data processing systems. I’ve come to genuinely despise the “Data Engineer” title (story for another time), so I won’t use it. But, on an average day leading our data infrastructure efforts at $coolNetworkingStartup I would, generally, do one or multiple of the following:
- Meetings, office hours, architecture chats, that sort of thing
- Write text with funny colors, these days usually
Python,Scala,go,typescript, andsql - Deal with actual infrastructure and tooling: K8s, Terraform, Docker, VPCs, EC2s, nix and other fun stuff
- Perhaps related, stare at AWS Cost Explorer or spreadsheets
- Babysit a bunch of OSS services, manage updates etc.
- Keep my project management stuff reasonably up to date and presentable
- And so on
I do have some reasonable overlap with sysadmin tasks, mostly because I’m a proponent of open software and hence, decided to use and host various OSS tools as part of our data stack. While most of that is very stable, it does occasionally require some mild Linux wizardry to get back on track.
Reasoning about complex systems↑
With that said, relatively rarely am I in the business of ssh’ing into a random Linux machine to check on nginx. Not saying it doesn’t happen - it just doesn’t happen very often.
And when it does happen, being able to reason about complex systems by means of understanding the underlying technology on more than a very rough surface level is tremendously helpful.
Self hosting all these services - especially, if they take you a look deeper into a rabbit hole than just copy pasting commands - will teach you a lot of new things that help with this.
Let me give you a small handful of real-world examples - often times, simple Linux administration basics can be useful. The best ways to acquire those is to either daily drive Linux (personally, I’m on macOS these days)… or self host and self manage servers.
For instance, knowing that setting swapiness is seldom useful and calling that out in pull requests or knowing that messing with LD_LIBRARY_PATH is a surefire way to frustration. However, being aware that both can be a valid tool to deal with obscure cases (for the latter, we mix poetry and nix and you can see where that is going) is helpful.
Of course babysitting and maintaining a distributed infrastructure (like Proxmox) or writing one from scratch is also helpful to maintain, design, and/or implement other complex distributed systems that span more than one concept.
One of my pet projects at work is an Apache Flink pipeline (itself an inherently distributed framework), written in Scala 3, that uses typeclass derivation via magnolia and avro4s to turn protobuf messages into Apache Iceberg via Kafka (it does a bit more, but these are the basics). This project involved, in no particular order, a more-than-surface-level understanding of the following concepts that aren’t core “programming” task, in addition to the core stuff (since it’s scala, stuff like tagless final):
VPCs and a bunch of networking, Kubernetes, GRPC, exactly-once/at-least-once semantics, eventual consistency, transactional locks, some compiler building, protobufs & schema evolution, Kafka (or general data storage replication and multi tenancy), blob storage, a ton of metrics & monitoring (and hence, timeseries databases for lack of a better umbrella term) and so on.

Here's a picture out our neighborhood barn cat, so you don't get too bored while we talk about protobuf compilers.
(Credit: by me)
Of course, if you are a reasonably seasoned engineer who has worked on distributed systems before, none of these topics will probably inherently new or scary - but the point is that a lot of them overlap with a lot of the things you deal with when you self host software - in fact, out of the 11 or so points I mentioned, I’m willing to wager I’ve dealt with at least 8 of them during my self-hosting adventures.
Lastly, as hinted to above, at $work I also “own” (isn’t that a horribly “corporate” word in this context?) several Open Source tools, which we self-host and dogfood on Kubernetes, such as Apache Superset. The parallels to what this article about should be relatively obvious. :-)
Things that broke in the last 6 months↑
Okay, cool, seems useful. But remember how I said “it’s a lot of work”? Well. Over the past 6 or so months, the following things happened (and I don’t believe that’s an exhaustive list):
- We had power outages and the UPS, which was supposed to be responsible for be backup power for the server + home network, just… didn’t work
- Because of that, our network - which has single point of failures - was down when a single server was down
- My VPS, the one server I outsource the operations of, was randomly offline for almost a week
- One of my Proxmox hosts crashed every single night, without fail, at 23:25 and came back online at 23:40
Things I learned (or recalled) in the last 6 months↑
So, allow me to rapid fire a bunch of things I did in the same timeframe, partially to fix some of these issues, and partially out of curiosity, and roughly what I learned and/or recalled by doing that.
You can self host VS Code↑
This is a simple, but neat one: The OS part of VS Code is something that runs in a browser. Same concept that powers GitHub’s codespaces, but self hosted: https://github.com/coder/code-server
Very useful to use VS Code on a device like an iPad or a Mac (or Windows) that wants a Linux box. Mine runs on Ubuntu.
Useful on an iPhone? Eh....
(Credit: by me)
I stumbled upon this while wondering if I can make my overpriced iPad Pro a bit more useful. Turns out, you can! Not saying you should, but you can.
UPS batteries die silently and quicker than you think↑
UPS batteries, at least consumer ones like my simple 1U Cyberpower 1500VA only last about 3 years. Mine, being 4 years old, were completely dead. While I’m conceptually aware that not everything is a long-lived lithium based powerhouse, I did not know they go to “unusable capacity” that quickly.
I learned that the hard way after getting hit by brown outs and power outages that are pretty common here, and seemingly randomly, “the internet” was down. Turns out, without a redundant DNS, the internet doesn’t work.
Changing these batteries was actually pretty straightforward (thanks to RefurbUPS).
Nowadays, I actually have powerst -test scheduled monthly and will take testing my other, analog backup batteries more frequently.
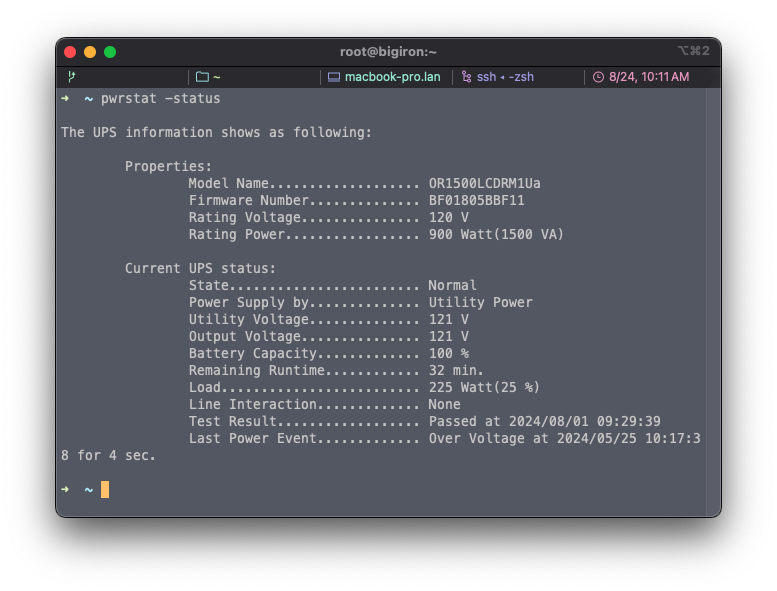
pwrstat.
(Credit: by me)
Redundant DNS is good DNS↑
We all know DNS is inherently redundant, globally distributed, and eventually consistent. But I actually never hosted 2 DNS caches at once.
The reason I never did - I use Pi-Hole, which runs dnsmasq. I also used it as a DHCP server to see which machine ran which DNS queries. So, by way of laziness and convenience, moving DHCP out of the Pi-Hole interface was annoying.
To fix that, I used RouterOS (Mikrotik) to set static IPs per device and VLAN/IP pool and re-enabled the DHCP server. I already did that for the non-home VLANs, since they use a public DNS and don’t use the Pi-Hole.
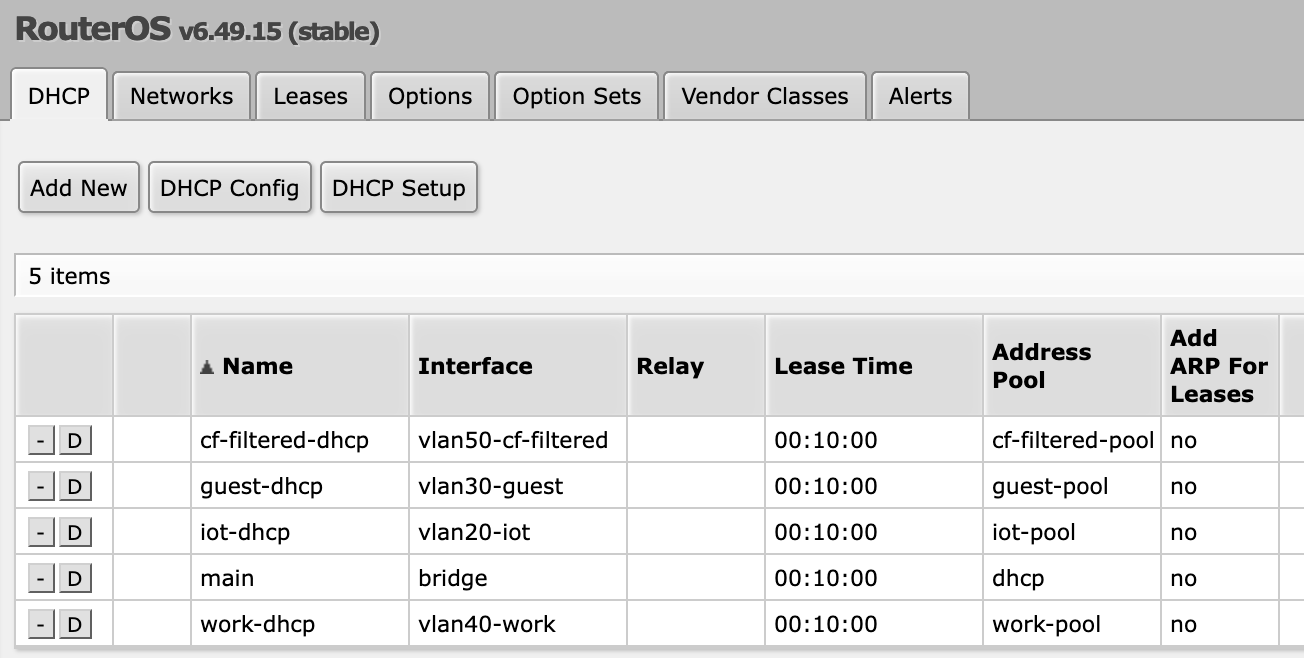
VLAN.
(Credit: by me)
I also used this as an opportunity to map IP ranges to physical devices.
I then used that mapping to map hostnames to IPs w/in the Pi-Hole:
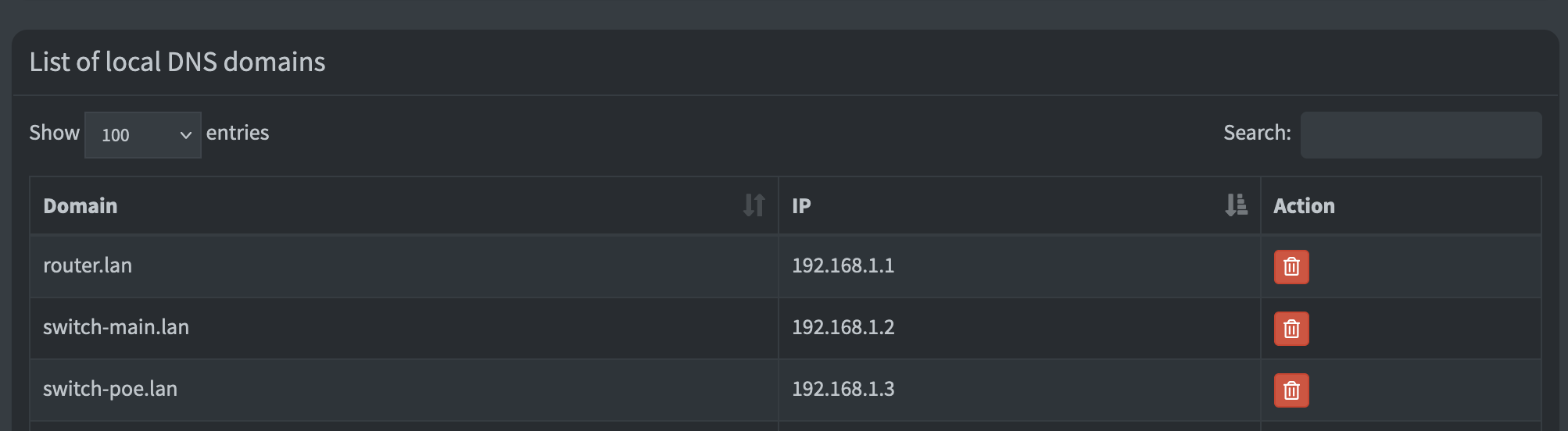
DNS Mapping.
(Credit: by me)
Then, it was just a matter of configuring the two Pi-Hole servers in RouterOS to make both available for clients. Poor man’s H/A!
Since we don’t add devices that often (and I add all services that need a DNS name to heimdall), it works well enough to grok Pi-Hole logs to manually copy over configs when something changes.
I’ve got it on my list to host orbital-sync to simplify this further.
At this point, you can also enforce the use of said DNS servers (which may be a good idea with kids or in a work setting) by means of firewall rules around port 53 UDP traffic. RouterOS can do that easily.
Raspberry PIs run ARM, Proxmox does not↑
Normally, Proxmox is x86 only.
But, this repo on GitHub preps Proxmox for ARM. Because of that, my little Raspberry Pi 5 is now a Proxmox node, which runs UniFi and one of the Pi-Holes.
Not recommended and unsupported? Sure! So is using zfs via an USB device. Still works (within reason)!

Promox nodes.
(Credit: by me)
I mentioned “Poor man’s High Availability” a second ago: Funnily enough, Linus Tech Tips recently made a video about Proxmox proper H/A VMs and failovers. My DNS setup is not that, but could be, since I now have 3 nodes, thanks to my frankenstein’d ARM node. And as they say: Three’s a quorum, baby!
As another little side tangent: The first time I dealt with “quorums” was in the early hadoop days, where manually configuring zookeeper, hdfs etc. and making sure your cluster can form a quorum was actually important. It was certainly more complicated than “just deploy this job to AWS” (and I don’t want to do that again), but it certainly taught me a lot about how the sausage is made!
zfs + Proxmox eat memmory and will OOM kill your VMS↑
Did you know OOM kills were “a thing” in $currentYear? Sure are! I run TrueNAS Scale with a SAS HBA in PCI passthru mode and had my machines OOM killed occasionally when both Proxmox backups + device backups where running.
Now, as a tangent on top of the tangent - running that config for TrueNAS is also unsupported/discouraged by TrueNAS, which wants to run on bare metal.
Anyways, Proxmox, by default, uses up to 50% of memory for the zfs cache, which, in combination with the VM being configured to use ~80%, didn’t work out too well in an environment with limited RAM - and one that consists of almost exclusively refurbished, old RAM sticks from other computers.
But, it turns out, you can configure that in the ZFS kernel settings!
echo 'options zfs zfs_arc_max="8589934592"' >> /etc/modprobe.d/zfs.confupdate-initramfs -uThis limits zfs to 8 GiB.
The mystery of random crashes (Is it hardware? It’s always hardware.)↑
One of my Proxmox hosts crashed every single night, without fail, at 23:25 and came back online at 23:40. Here’s the monitoring:
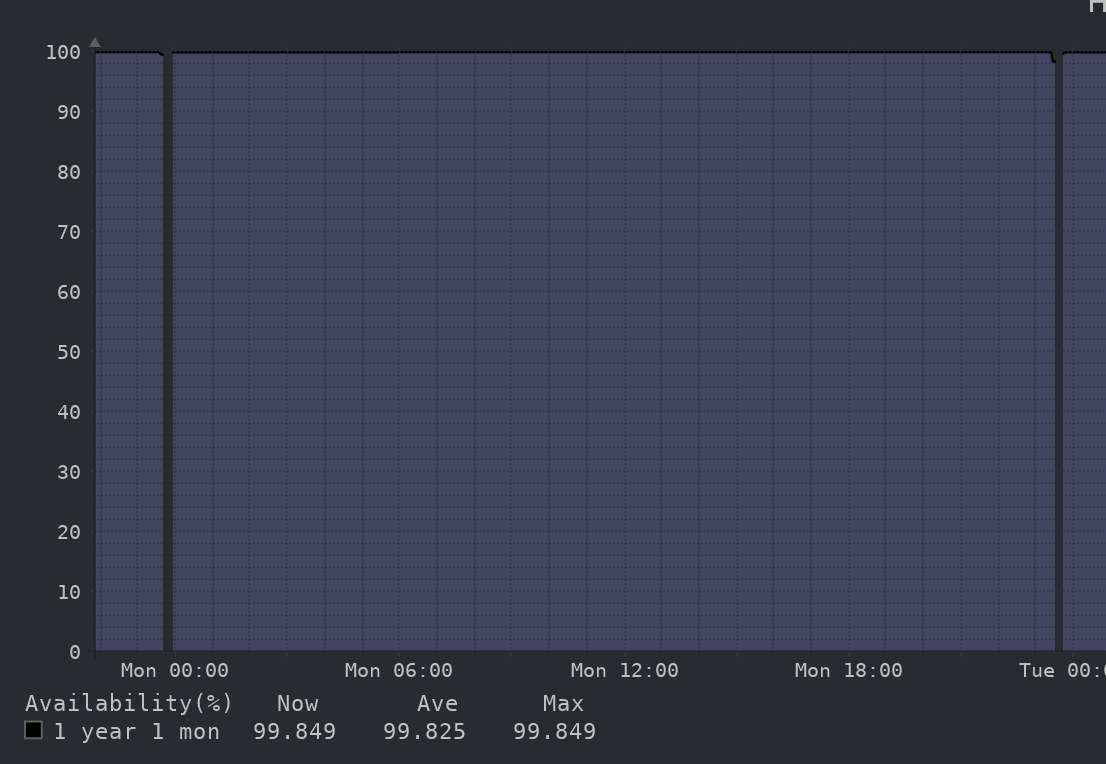
TBD.
(Credit: by me)
While it did restart automatically, including the VMs, it of course couldn’t decrypt the zfs pool. I only noticed when the TimeMachine backups on my Mac were failing!
Well, sorting through logs revealed: 23:25 is when another Proxmox nodes backs up its VM to that server, to a single, non-redundant, ancient harddrive, with SMART values like this:
Error 4 occurred at disk power-on lifetime: 27469 hours (1144 days + 13 hours) When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 04 51 00 ff ff ff 0f
Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- ea 00 00 00 00 00 a0 00 6d+03:38:11.728 FLUSH CACHE EXT 61 00 08 ff ff ff 4f 00 6d+03:38:11.726 WRITE FPDMA QUEUED 61 00 08 ff ff ff 4f 00 6d+03:38:11.726 WRITE FPDMA QUEUED 61 00 08 ff ff ff 4f 00 6d+03:38:11.725 WRITE FPDMA QUEUED 61 00 b0 ff ff ff 4f 00 6d+03:38:11.725 WRITE FPDMA QUEUED…which then caused weird deadlocks and such and the machine became unresponsive and got killed.

LibreNMS monitoring.
(Credit: by me)
Replace drive, problem solved. Funny how that works.
$BigHardDrive will tell you to only use shiny, new, fancy, expensive drives, but the man with the server rack in the basement tells you that you can, in fact, re-use your ancient, assorted pieces of hardware for ultimately unimportant backups with no almost no issues!
SNMP(v3) is still cool↑
I live precariously through reminders. One I had on my list for a while was “automate network mapping and alerts”. Turns out, a solved problem, even without the modern monitoring & tracing solutions from Datadog (which, for the record, I love), Jaeger, Prometheus and the like.
These graphs above from the decaying HDD? LibreNMS!
Uses Simple Network Management Protocol (SNMP). An ancient protocol from the 80’s that does exactly that: Monitors your stuff. I just never bothered setting it up, since it is somewhat of an arcane protocol to modern eyes. Not that I allow inbound traffic (we have ngrok for that), but a paranoid sysadmin is a good sysadmin.
SNMP depends on secure strings (or “community strings”) that grant access to portions of devices’ management planes. Abuse of SNMP could allow an unauthorized third party to gain access to a network device.
SNMPv3 should be the only version of SNMP employed because SNMPv3 has the ability to authenticate and encrypt payloads. When either SNMPv1 or SNMPv2 are employed, an adversary could sniff network traffic to determine the community string. This compromise could enable a man-in-the-middle or replay attack.
…
Simply using SNMPv3 is not enough to prevent abuse of the protocol. A safer approach is to combine SNMPv3 with management information base (MIB) whitelisting using SNMP views.
https://www.cisa.gov/news-events/alerts/2017/06/05/reducing-risk-snmp-abuse
I have all devices (that support it) on the network in LibreNMS, using the most “secure” version of the protocol, V3.
It does everything a cool, modern, SaaS based tracing and monitoring service does, for free. Well, maybe not all of it - but it’s delightfully in depth. Other options (not necessarily mutually exclusive) are zabbix and munin, both of which I played with before, but never stuck to. This is a deceptively deep field, turns out, and not one I’m very knowledgeable about.
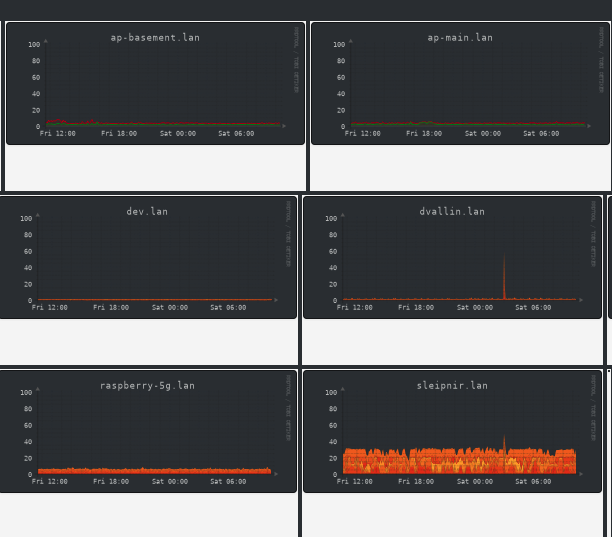
LibreNMS.
(Credit: by me)
But I do like graphs and pretty dashboards.
Don’t trust your VPS vendor↑
My VPS, hosted by Contabo, randomly went down for almost 4 days. You could not read this blog.
Only VNC through a different IP worked. I was able to talk to my server, which I paid for continuously since 2014, only via VNC. Nothing else worked - ping, SSH, nothing. And I pride myself in writing detailed support tickets and check everything I can myself - this time, it actually wasn’t DNS. :-)
For a short timeline of events: First, I raise a ticket outlining the problem, including a copy of the DNS config.
I’ll refrain from pasting the verbatim interactions here, but their response boiled down to
Your problem sounds like a case of not having the DNS server set.
… followed by a few steps to set the Google DNS servers via resolv.conf.
Naturally, DNS was the first thing I checked. See above. My response included another copy (this time a screenshot) of my DNS configuration and a friendly note that I can’t install apt packages, since the machine is cut off from anything outside their data center.
I tried to offer more insights by doing some more digging. Turns out, I couldn’t even ping the IP directly (i.e., without DNS involvement). It seems like my ISP and their data center could not talk.
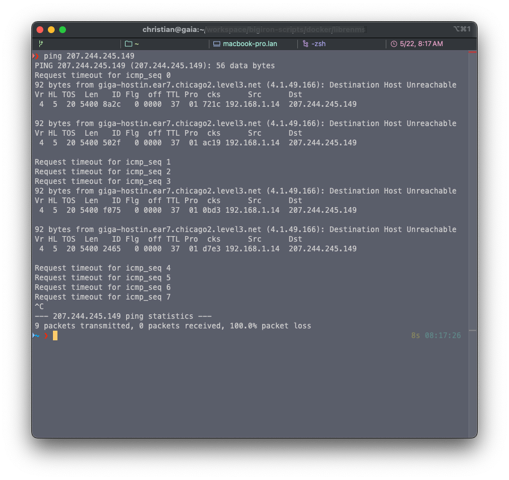
External network path says no.
(Credit: by me)
As well as the fun observation that the VPS couldn’t talk to anything external. The only reason VNC worked is that this would tunnel it through a different machine in the same DC.
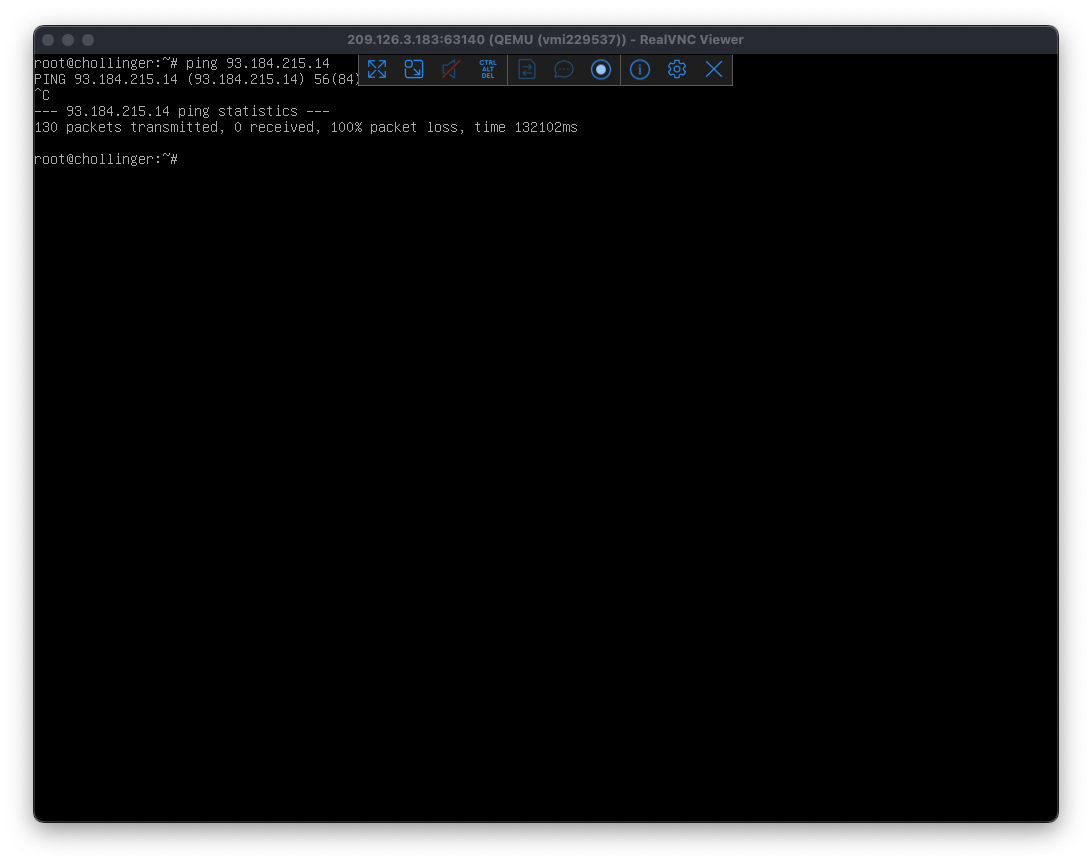
Ping says no internally.
(Credit: by me)
93.184.215.14 is example.org. This would never time out, since I let it run overnight. And yes, I did all of this debugging with netcat too, given the limitations of a simple ping.
More curiously, an arp scan gave me back 207.244.240.1, which is their data center in Missouri. Which, while available, was spotty to reach from the outside at best:
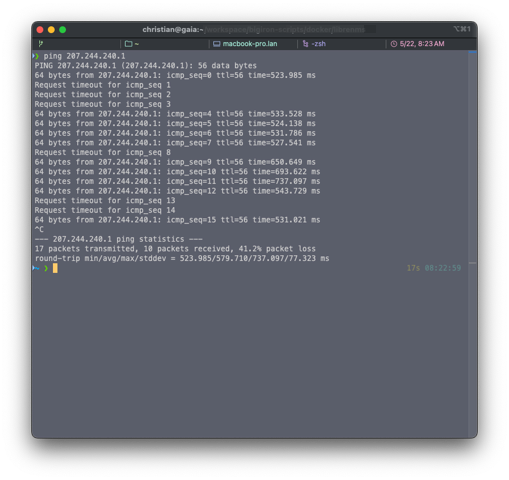
Flakey.
(Credit: by me)
Everything here pointed at a larger network issue on their end, and my server had been offline for 48 hrs.
2 days later, my own options exhausted, the machine is suddenly back online - in a different DC, from what I can tell. I made no further changes and worked on on a migration to Hetzner instead (see below). I get this email:
Thank you for your patience. We checked your VPS M SSD/ It is reacting to Ping requests, SSH and VNC is accessible as well. Therefore we assume that the issue is already solved. Kindly check your side again.
…awesome. I did nothing (see above - don’t think I could have!) and it suddenly works.
I’m certainly not above admitting if I did mess something up - I’ve done it in this article and on this blog many, many times and I do mess up sysadmin stuff frequently - but this time, I promise you I’ve made zero changes to the box before this happened, neither before it magically was fixed.
I don’t expect 99.999% availability from a more budget VPS, and they do only “advertise” (I use this term lightly - it’s hidden in their T&C) and SLA of 95%, which means they allow for over 18 days of downtime a year.
(1) The Provider will ensure that the physical connectivity of the object storage infrastructure, webspace packages, dedicated servers, virtual dedicated server and VPS is available at an annual average rate of 95%.
Unfortunately, this interaction, not necessarily the downtime itself was so bad that I stopped recommending Contabo entirely and since moved to Hetzner - and, of course, my own physical hardware, which had 99.995% uptime:

Uptime.
(Credit: by me)
Realistically, it’s probably more like 98% long-term, but that involves me actively breaking things. Make of that what you will.
Gotta go fast↑
So, because of that, I looked for alternatives. I wanted a cheap VPS in the US for latency reasons, with basic creatue comfort. Eventually, after much deliberation, I moved to Hetzner, another German company with at least some North American data centers, on their small, $7ish/mo, CPX21 VPS.
Much to my surprise, that machine was faster in benchmarks than my (nominally much more powerful) Contabo VPS:
sysbench --threads=4 --time=30 --cpu-max-prime=20000 cpu runGot me
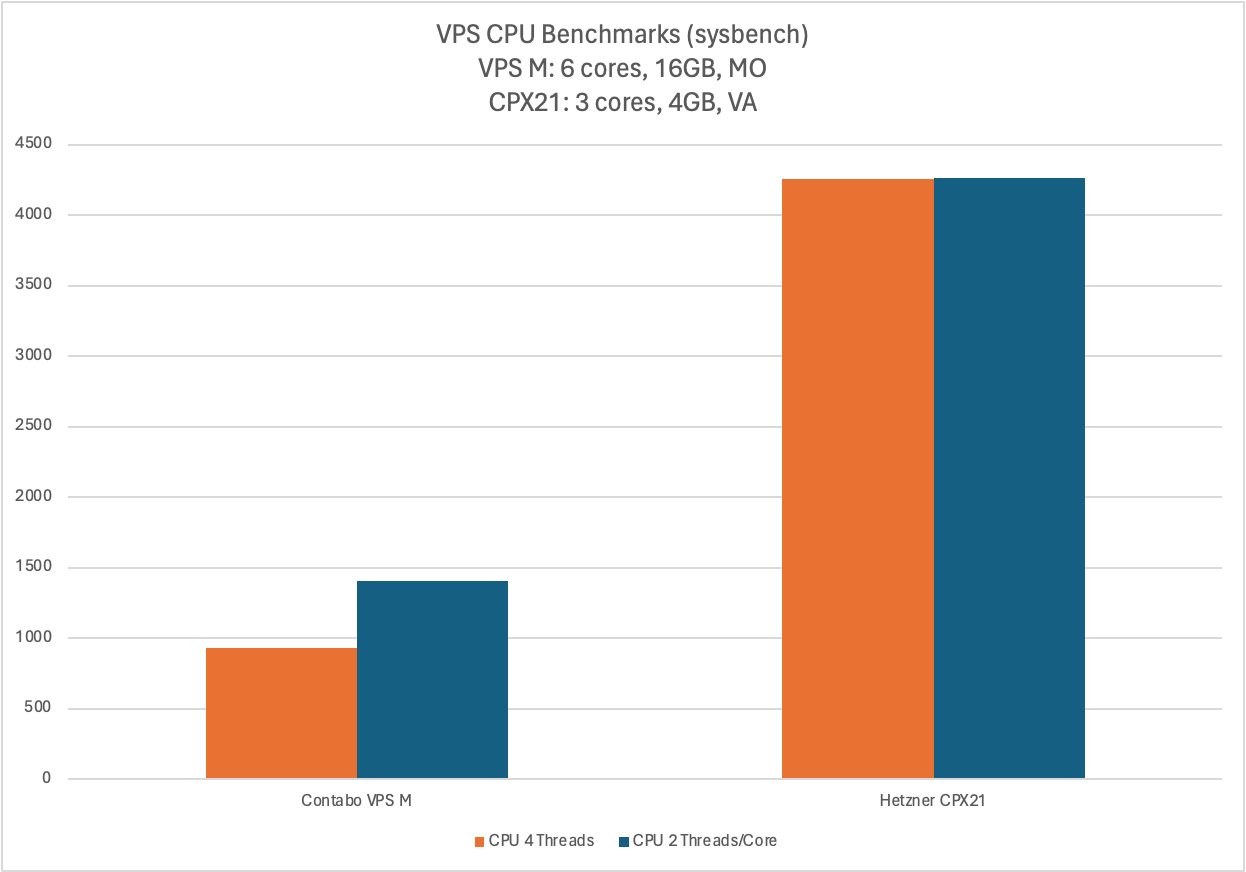
VPS Benchmark 1/2.
(Credit: by me)
And
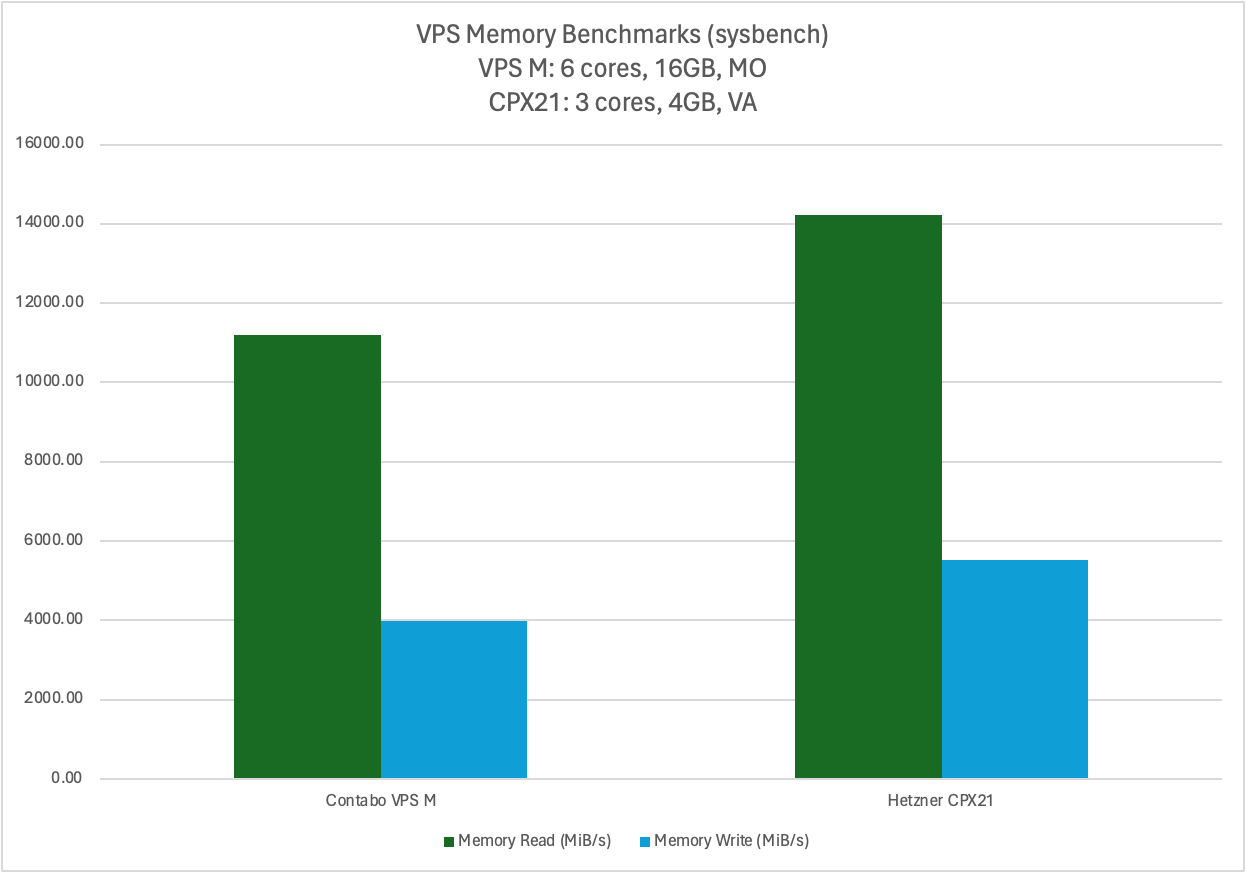
VPS Benchmark 2/2.
(Credit: by me)
Yes, synthetic benchmarks aren’t perfect, but they also certainly aren’t completely meaningless.
Again, make of these numbers what you will.
CIFS is still not fast↑
Unfortunately, the server came with a 80 GB SSD. That’s only about 29,000 3.5” floppy disks! Remember, this server runs Nextcloud which, inherently, requires a lot of storage.
My MacBook uses 1.2/2 TB, my Proxmox cluster has something like 50 TB combined capacity (in fairness, lots of redundancy), and even my phone is using ~200GB.
I stumbled upon Hetzner’s “StorageBox”. Cool concept: Basically what rsync.net does, but German. You basically get a dumbed down terminal and a slow, shared disk for very little money at all: ~$4/TB! Unfortunately, no US locations.
You can access these disks via FTP, SFTP or SCP (aka SSH), WebDAV, various backup tools like borg and so on.
Overall a pretty promising concept, but once you need to attach said disk to a server to make the local storage bigger and usable w/in Nextcloud, your options are somewhat limited and the official docs recommend samba/cifs. sshfs is a valid alternative, the project is in maintenance mode, but I tested it anyways. I suppose conceptually you could make WebDAV work.
In any case, I tried using the official approach and benchmarked a bit because it certainly felt slow.
Well, that’s because it was. Here’s three benchmarks, two with cifs (V3), with a strict and loose cache, as well as sshfs.
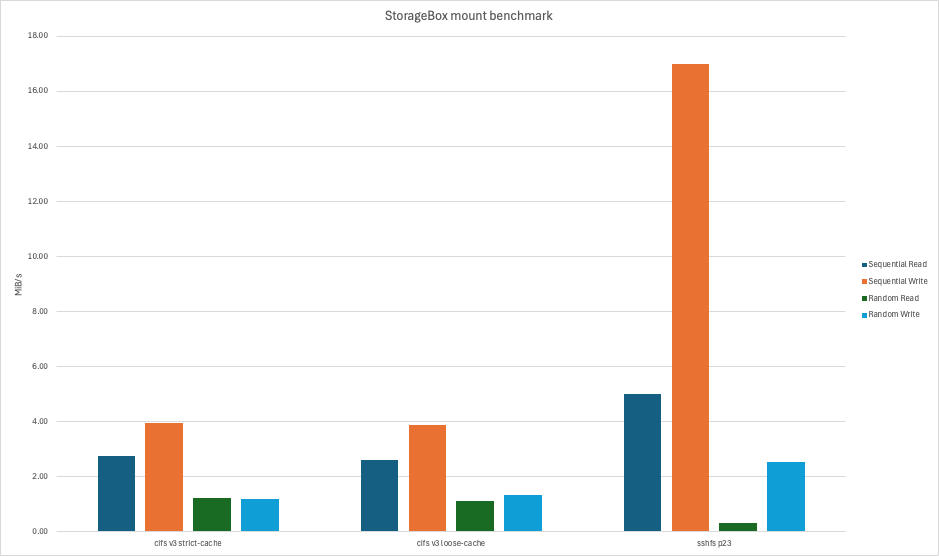
Storage Benchmark 1/2.
(Credit: by me)
Here’s what I used to test this:
SIZE="256M"# Sequentialfio --name=job-r --rw=read --size=$SIZE --ioengine=libaio --iodepth=4 --bs=128K --direct=1fio --name=job-w --rw=write --size=$SIZE --ioengine=libaio --iodepth=4 --bs=128k --direct=1# Randomfio --name=job-randr --rw=randread --size=$SIZE --ioengine=libaio --iodepth=32 --bs=4K --direct=1fio --name=job-randw --rw=randwrite --size=$SIZE --ioengine=libaio --iodepth=32 --bs=4k --direct=1Not a new finding either, as I’m not the first to benchmark this.
In any case, that’s pretty slow. The combination of a slow protocol - cifs - a slow box, and cross-Atlantic latency didn’t make this particularly attractive.
To give you some perspective, here’s the same chart with the same benchmark run on a local Proxmox VM:
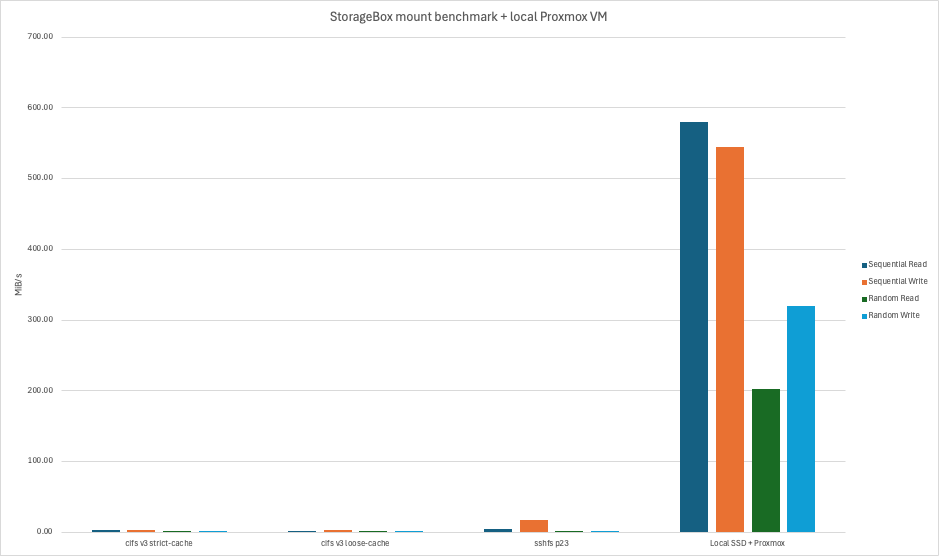
Storage Benchmark 2/2.
(Credit: by me)
Blob storage, blob fish, and file systems: It’s all “meh”↑
Now, not even using a “disk”, that’s what all the cool kids do nowadays. They simply throw away almost all the advantages of modern, fast, local storage with a high quality, tested, atomic, error correcting (…) file system by, get this, not having a file system and call it “object” (or “blob”) storage and get none of those features, but a lot of storage for cheap!
Tangent: Since the world “blob” is now indexed, please remember the following before you shame a helpless fish for the failures of your storage architecture:

Poor fish.
(Credit: by Naila Latif)
Anyways - despite the drawbacks, it’s really not a new concept. Professionally, I’d use fast NVMe drives for stuff like developer machines, databases and the like, regular SSDs for less intense application servers, and blob storage for slow-but-cheap data storage and distributed query engines, with optional caching where required. Most of my Data Platform project in the past ~10 years have been based on S3/GCS/etc., and often stored many hundreds of TiB (if not PiB) of data.
However - these storage systems are not file systems and trying to pretend s3 and zfs are similar because they both store files (like some sort of deranged, surface level 🦆-typing) is not going to end well.
But, given my access patterns - storing files and accessing them every once in a while by hand and not hosting a database on it, just like I would use a slow, HDD based local file server, I still went looking for blob storage options to store just my Nextcloud data.
Your options essentially are the big providers, like AWS, where 1TB runs you roughly ~$20-24/mo, depending on the provider and region.
Third party alternatives that implement the same protocol, say s3, are mostly Wasabi and Backblaze.
Wasabi charges a minimum of $6.99/mo (which is the price per TB) and 90 days minimum storage (i.e., deleting data doesn’t help). Backblaze is cheaper on paper at $6/mo/TB, but they do charge $0.01/GB egress over 3x the average monthly data stored, which is included with Wasabi.
Given that I spent $35 egress to get my 500GB server backups out of S3 during the migration and after reading this, I went with Wasabi and moved my files there:
Wasabi.
(Credit: by me)
And then used the Nextcloud external storage interface to mount the drive.
And what can I say, it… works. It behaves just like S3 does: If you need to list a lot of files or do anything with a lot of small files, it’s a huge pain and will not be fast. That’s the reason the semi-official recommendation for deleting large amounts of small files is to use bucket lifecycle policies.
For $6.99 a TiB, it works okay. Listing files on a cold cache (e.g., a new device) is slow as molasses, and searching for files puts you entirely at the mercy of your index (compared to a find or grep on a local NVMe storage).
Seeing this screen for several seconds is normal:

Nextcloud on iOS.
(Credit: by me)
In all fairness, this is really only a problem on mobile devices, since I have all my files downloaded on my Mac anyways.
I might still try rsync.net, which clocks in at $12/mo/TB.
CrowdSec↑
Last but not least, do you remember fail2ban? You should, because it’s still very much an active project that should probably stay the default recommendation for simple intrusion prevention.
But, setting up a new server, I figured it would be worth checking some newer tools, namely CrowdSec (not to be confused with CrowdStrike :-) ) which describes itself as
a free, modern & collaborative behavior detection engine, coupled with a global IP reputation network. It stacks on fail2ban’s philosophy but is IPV6 compatible and 60x faster (Go vs Python) (…)
The neat thing about CrowdSec is that, as the name implies, the threat detection patterns are being shared (anonymously) with their community, which (allegedly) yields a much better threat detection. It also has a plugin hub, with “bouncers” for various tools.
It also comes with a neat cli that gives you stats about what it’s doing:
cscli metricsWhich, for instance, will tell me it banned 33 IPs for crowdsecurity/CVE-2019-18935, a rule for this CVE.
Overall, I’m a fan - it certainly feels like a natural evolution of fail2ban (even though I suspect they could co-exist) and as long as the company behind it doesn’t exploit its user base at a certain point, I’ll stick to it.
Conclusion↑
If you’re a software engineer, I recommend self hosting things. You learn a whole bunch of things through forced exposure to problems that you’ll be less likely to encounter in your day job, which in itself is a benefit. Even better, I do believe you’ll wind up using at least some of these things in your day job eventually, provided you work on something vaguely backend related.
By hosting stuff yourself, also get a reasonable level of autonomy - or, at the very least, some hedging - against the corporate dream of your entire life being a perpetually rented subscription. I think that’s nice.