Blog posts tagged with 'bash''
- Bad Data and Data Engineering: Dissecting Google Play Music Takeout Data using Beam, go, Python, and SQL
2021-02-28: On the joy of inheriting a rather bad dataset - dissecting ~120GB of terrible Google Takeout data to make it usable, using Dataflow/Beam, go, Python, and SQL.
data engineeringlinuxbashgopythondataflowbeambig data
- How I built a (tiny) real-time Telematics application on AWS
2019-08-07: In 2017, I wrote about how to build a basic, Open Source, Hadoop-driven Telematics application (using Spark, Hive, HDFS, and Zeppelin) that can track your movements while driving, show you how your driving skills are, or how often you go over the speed limit - all without relying on 3rd party vendors processing and using that data on your behalf...
awsbashcloudiotkinesislambdalinuxprogrammingpython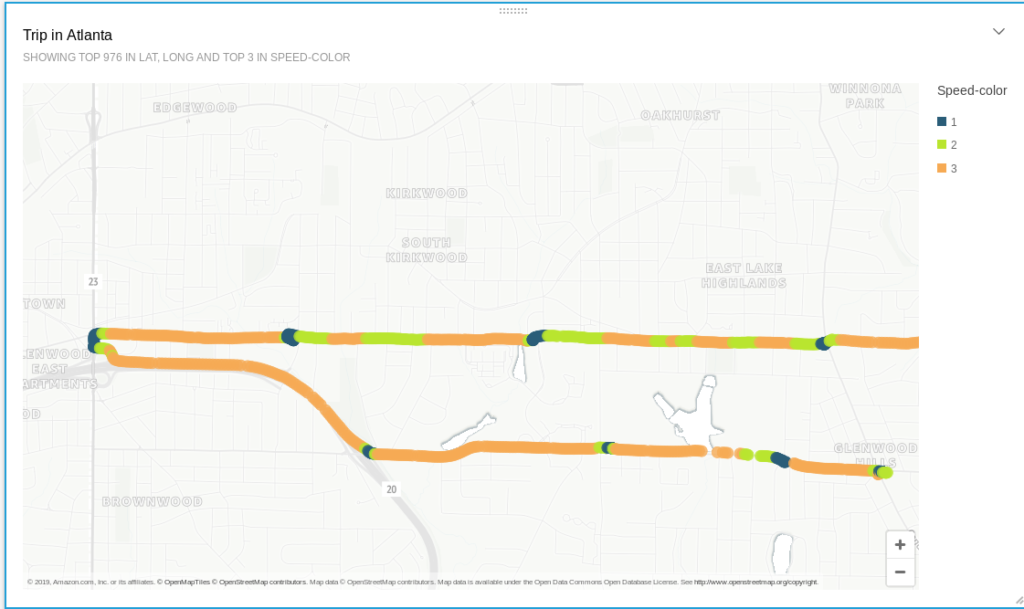
- Building a Home Server
2019-04-11: In this article, I’ll document my process of building a home server - or NAS - for local storage, smb drives, backups, processing, git, CD-rips, and other headless computing...
linuxbashnetworkingbig datadebiancentosencryptionluksprivacysecuritywindowsserversysadmin