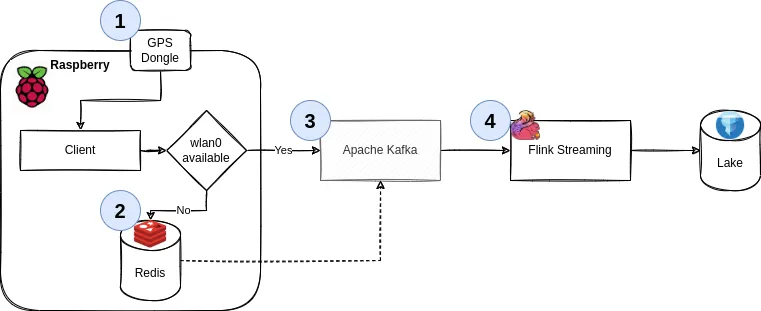
This is Part 2. Part 1 can be found here, where we discussed goals and architecture, built a custom RaspbianLinux image, implemented the client part of the application in Python, using gpsd, with concepts borrowed from scala.
In Part 1, we built a good execution environment in the frontend, we can do the same for the backend - i.e., the Kafka cluster and storage. This is where things go from “low level stuff” to “pretend a Docker container can abstract the complexities of distributed systems away”. I’m still very grateful for it, having set up multiple bare-metal Hadoop environments in my time. This is easier for protoyping and at-home use.
Since we don’t need a large, fancy cluster & the server isn’t reachable from the internet anyways (i.e., we don’t need auth), we can get away with the following on your server.
Terminal window
# Add your user - we did this in the image earlier, but you might want this locally too
sudouseradd-m-gusers-Gdockertelematics
sudopasswdtelematics
sudosu-telematics
# Take the default docker-compose.yaml (see below)
vimdocker-compose.yaml
# Start it
docker-composeup-d
# Start a topic
dockerexecbroker\
kafka-topics --bootstrap-serverbroker:9092\
--create\
--topictelematics
This is also how I run Kafka locally at work (just via podman) - it’s fantastic to have on your laptop if you’re a heavy Kafka user.
Please note the inclusion of EXTERNAL_DIFFERENT_HOST to ensure the initial Kafka broker (bigiron.lan:9092) returns the correct address for the client to connect to. See here for an explanation. If you don’t see this, the next step will yield something along the lines of:
Terminal window
WARN [Producer clientId=console-producer]Connectiontonode1 (localhost/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
As bigiron.lan:9092 tells us “hey, talk to localhost:9092”, which of course, isn’t the correct machine. bigiron.lan, of course, is curtesy of my DNS resolver knowing about bigiron’s IP.
You can do this via docker as well, I think. I just chose not to - I like my cli tools be cli tools and the services to be services (i.e., containers nowadays). I’ve run Linux servers for well over a decade and docker has been a godssent for services.
As much as I like simple docker deploys, I’m sure we can all agree that this is not the way you’d deploy this in production @ work… but the server in my basement is also not exactly a data center.
Note the type for lat and lon as DECIMAL. Most people are familiar with very strict types in sql, but somehow not in e.g. Python. We’ll get back to that momentarily. For this example, consider the following:
34.42127702575059, -84.11905647651372 is Downtown Dawsonville, GA. (34.4, -84.1) is 2.2 miles away, (34.0, -84.0) is 40 miles away in Lawrenceville, GA. That’s DECIMAL(11,8) vs DOUBLE vs FLOAT in MariaDB (the latter, more or less, but it drives home a point).
If you used something like Spark, Storm, Heron, or Beam before, this is nothing new conceptually. Since I don’t have the space or time to talk about when you’d use what, let’s just leave it at this: Stateful, real-time stream processing with either bounded or unbounded streams and several layers of abstraction that allow you to write both very simple, boilerplated jobs, as well as complex stream processing pipelines that can do really cool stuff.
What makes Flink interesting for this project in particular (besides the fact that I want to play around with it) is twofold:
If we ever wanted to graduate from MariaDB, Flink has an Apache Icebergconnector, as well as a JDBC connector, which makes writing data much easier than having to roll our own.
Secondly, the way it approaches snapshots: While I invite you to read the linked tech doc, a (rough) two sentence summary is:
A barrier separates the records in the data stream into the set of records that goes into the current snapshot, and the records that go into the next snapshot. […]
Once the last stream has received barrier n, the operator emits all pending outgoing records, and then emits snapshot n barriers itself.
This means, we can process with exactly-once semantics; remember that our producer guarantees are “at least once”, so the best stateful snapshotting process in the world won’t save us from producing duplicates if we introduce them ourselves. [1]
However, unless latency is a top priority (which here, it clearly isn’t, as we’re already caching most of our data and have at most a handful of users, one for each vehicle in the household), adding a handful of ms of latency to our stream for the benefit of getting exactly-once semantics will greatly increase the resulting data quality.
Also, Flink has a neat, persistent UI, which e.g. Spark still really doesn’t have.
Note: We need scala2.12.16, not 2.13.x:
Terminal window
sdkusescala2.12.16
sbtcompile
[1] You’ll quickly note that, while possible (and I called out how to do it), the pipeline presented herein isn’t actually following exactly-once semantics yet. I plan to add that in the future after I replace MariaDB - currently, the abstraction from a full database to a decoupled storage and compute engine is too weak to spend the effort in making this exactly-once, since I’d have to do it again later on.
I’m adding a handful of, in my opinion, good-practice scala libraries to Flink, which is not something you’ll see in many tutorials for Flink or any Data Engineering articles. Most of them are inspired by Gabriel Volpe’s excellent “Practical FP in Scala” book.
Since we probably don’t want to write our own SerDe by hand, we can use derevo to automatically derive encoders and decoders by using some compiler annotations:
@derive(encoder, decoder)
finalcaseclassGpsPoint(
tripId: ID,
userId: ID,
lat: Latitude,
lon: Longitude,
altitude: Altitude,
speed: Speed,
timestamp: EpochMs
)
Which is neat, because now, we can get import io.circe.syntax.EncoderOps into scope and say:
The type of the function is A without any bounds (if you’re suspicious, carry on).
The arguments ask for three Strings, which could new @newtype’d if you want to, and all three simply refer to standard Kafka settings we’ve already discussed. We’ll refactor this in a minute once we load a config file.
defbuildSource[A](
bootstrapServers: String,
topics: String,
groupId: String
)(implicit
deserializer: Decoder[A],
typeInfo: TypeInformation[A]
):KafkaSource[A] =
The last section asks for 2 implicits: A Decoder[A] and TypeInformation[A]. These are, essentially type bounds that say “the type A must have a Decoder and TypeInformation available and in scope”.
A Decoder can be provided by derevo, see above. TypeInformation can be inferred as such:
This means, we can also express this by means of a type class:
defbuildSource[A:Decoder:TypeInformation]
Which would be simply sugar for the aforementioned implicits. As long as we have everything in scope, we simply define very clear bounds for the type of A, meaning if you don’t tell it how to deserialize your weird custom data structures, it won’t to it.
Unsurprisingly, we’ll now use the aforementioned implicit Decoder[A] to build a concrete instance of a KafkaRecordDeserializationSchema by taking the incoming, raw Array[Byte] from Kafka and piping them through circe back to JSON back to a scala object:
This can be done via the standard JDBC connector. Keep in mind that in order to support exactly-once delivery, your database needs to support the XA Spec.
That being said, all we need to do in the Flink world is convert some Java to scala syntax.
You’ve seen it in the previous section, but we’ll use pureconfig for reading config files. To keep it simple, we’ll define a minimal model and read it from resources/application.conf:
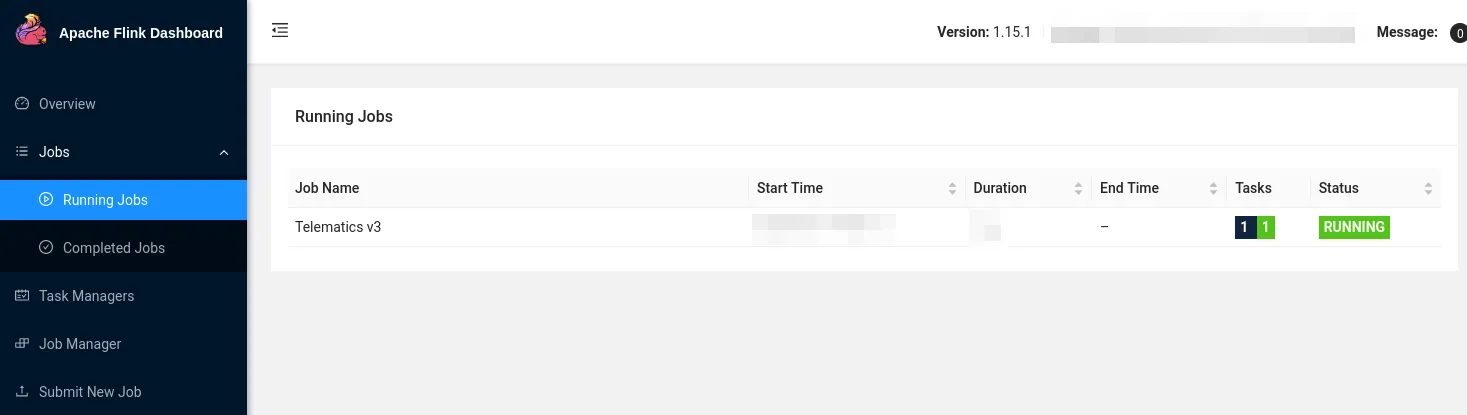
We’ll run this on a simple, single-node cluster in session mode, which allows us to submit jobs towards the cluster. Once again, we can containerize all this:
This was a matter of plugging in the Pi into a USB port and checking that everything worked:
Truck workstation..
The only mishap here was the fact that we didn’t set up any udev rules that would ensure we can always talk to e.g. /dev/ttyGps, rather than /dev/ttyACM$N, where $N might not always be consistent, resulting in a pack on GPS connectivity.
udev is a userspace system that enables the operating system administrator to register userspace handlers for events. The events received by udev’s daemon are mainly generated by the (Linux) kernel in response to physical events relating to peripheral devices. As such, udev’s main purpose is to act upon peripheral detection and hot-plugging, including actions that return control to the kernel, e.g., loading kernel modules or device firmware.
This was distinctly one of the weirder developer environments I’ve worked in - during my test trip(s) (one graciously done by my significant other), having a Raspberry Pi and an obnoxiously blinking GPS dongle in the middle console is odd to say the least. Then again, probably less irritating than Carplay and others, so there’s that.
As seen in the TV show...?.
Also, I’ll buy whoever recognizes this location a beer at the next conference. It is, unfortunately, not our back yard.
I’ll admit it - the drive to the lakes wasn’t the only test I’d have to do. There were some other issues encountered during these road tests, and I’ll sum them up briefly:
Due to the nature of the caching mechanism, it takes quite a while to the data to be sent back to Kafka. This means, if you unplug the Pi and plug it back in inside, chances are, it won’t get a GPS fix; this means the buffer doesn’t fill and hence, our data is stuck in redis. The fix is trivial - if there’s data in redis, send that after a restart.
In a similar vein, not getting a GPS fix can cause the poll_gps() loop to practically deadlock. We can time out that process, but it makes little difference, because…
…I made a fundamental error by using time.sleep() within the loop. Rather, we should be relying on the GPS receiver’s update frequency - 1Hz - because otherwise we’ll get the same record from the buffer over and over again. We need to correct drift. See below.
However, sometimes a cheap USB GPS dongle simply doesn’t get a good signal and hence, does not report GPS data or, worse, somehow does a cold boot and needs a new satellite discovery process & fix. This happened several times, where I see the first GPS point 5 to 10 minutes after I leave the house. And while where we live has been described as “chicken country” to me, in reality, it isn’t what I’d call remote - certainly not some odd GPS blind spot where it’s impossible to get enough satellites for a signal.
The Kafka client was created prematurely and assumed WiFI connection was a given, meaning the service couldn’t start up again after a stop at Costco outside WiFi range.
An indentation error & lack of unit test (despite pretty good coverage) caused the cache to be deleted prematurely.
Lastly, another fundamental hardware issue; Postmortem can be found here.
Turns out, writing a fully cached, offline system isn’t as easy as I thought.
What we did originally: yield, do a bunch of expensive operations, time.sleep(1), go back to gpsd and ask for the next record.
However, that next record comes in at a frequency of 1-10Hz, and our other operations (especially calling subprocess can be relatively slow). So, if we encounter drift, i.e. where we’re falling behind with processing records, we have to skip them - otherwise, we’ll never catch up.
# Account for drift, i.e. the rest of the program lags behind the gpsd buffer
# In that case, just throw away records until we're current
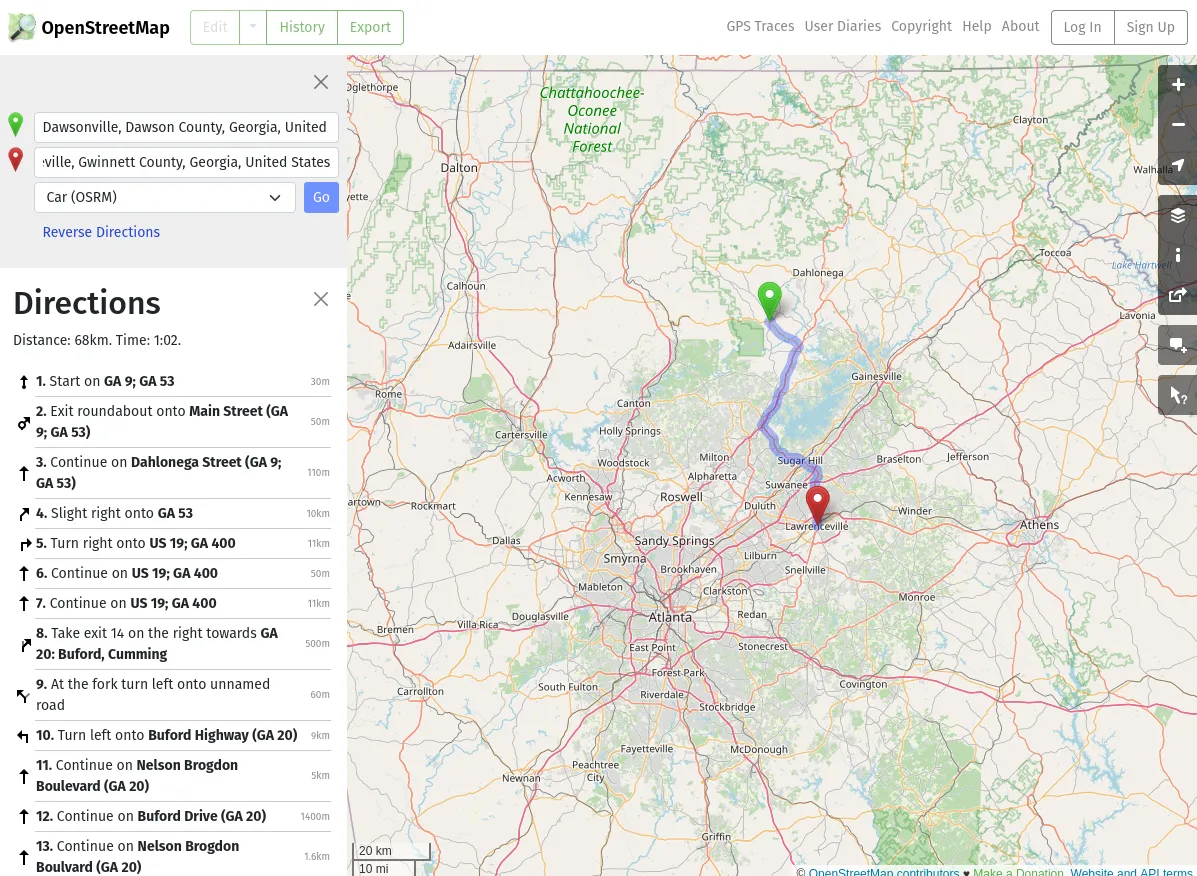
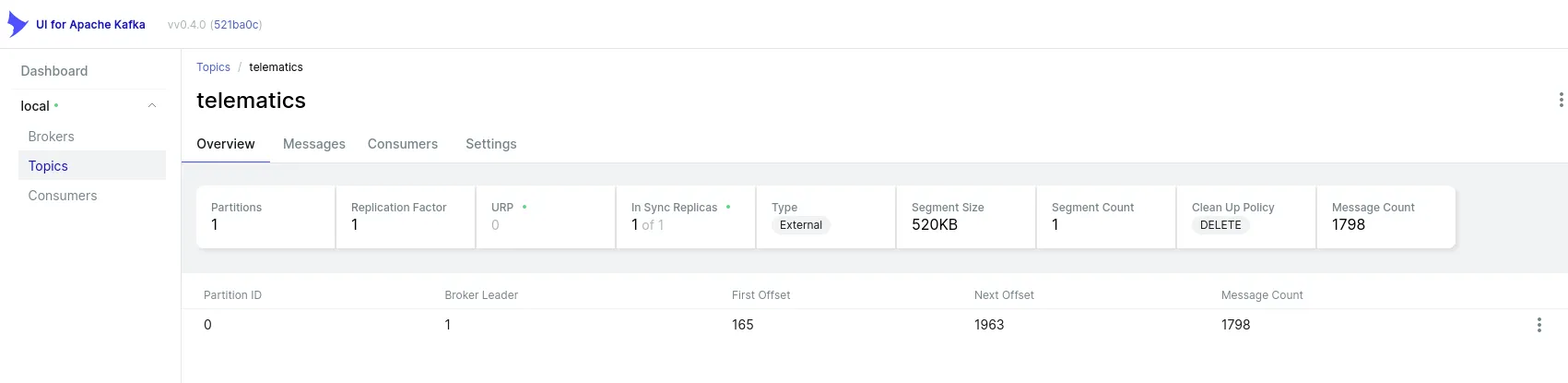
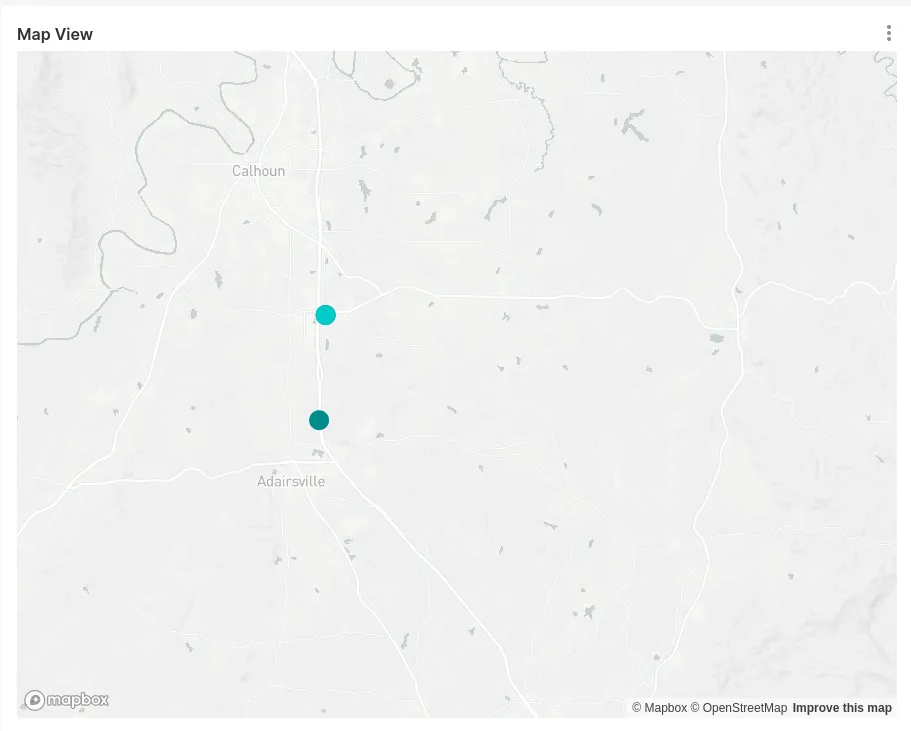
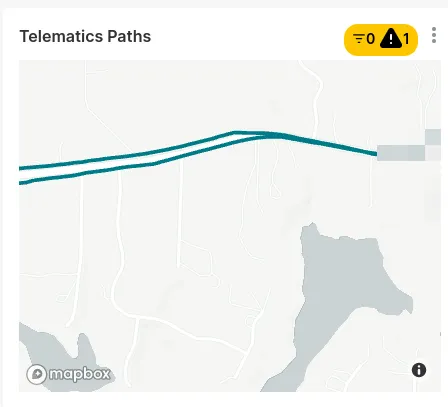
While the above rings true and was an issue, after fixing this and driving a solid 200mi one Saturday, my GPS map looked like this: [1]
The distance between those points is only a handful of miles, but I’m cropping out the rest for privacy reasons. On the real map, there’s 6 or so more points - one for each stop or restart.
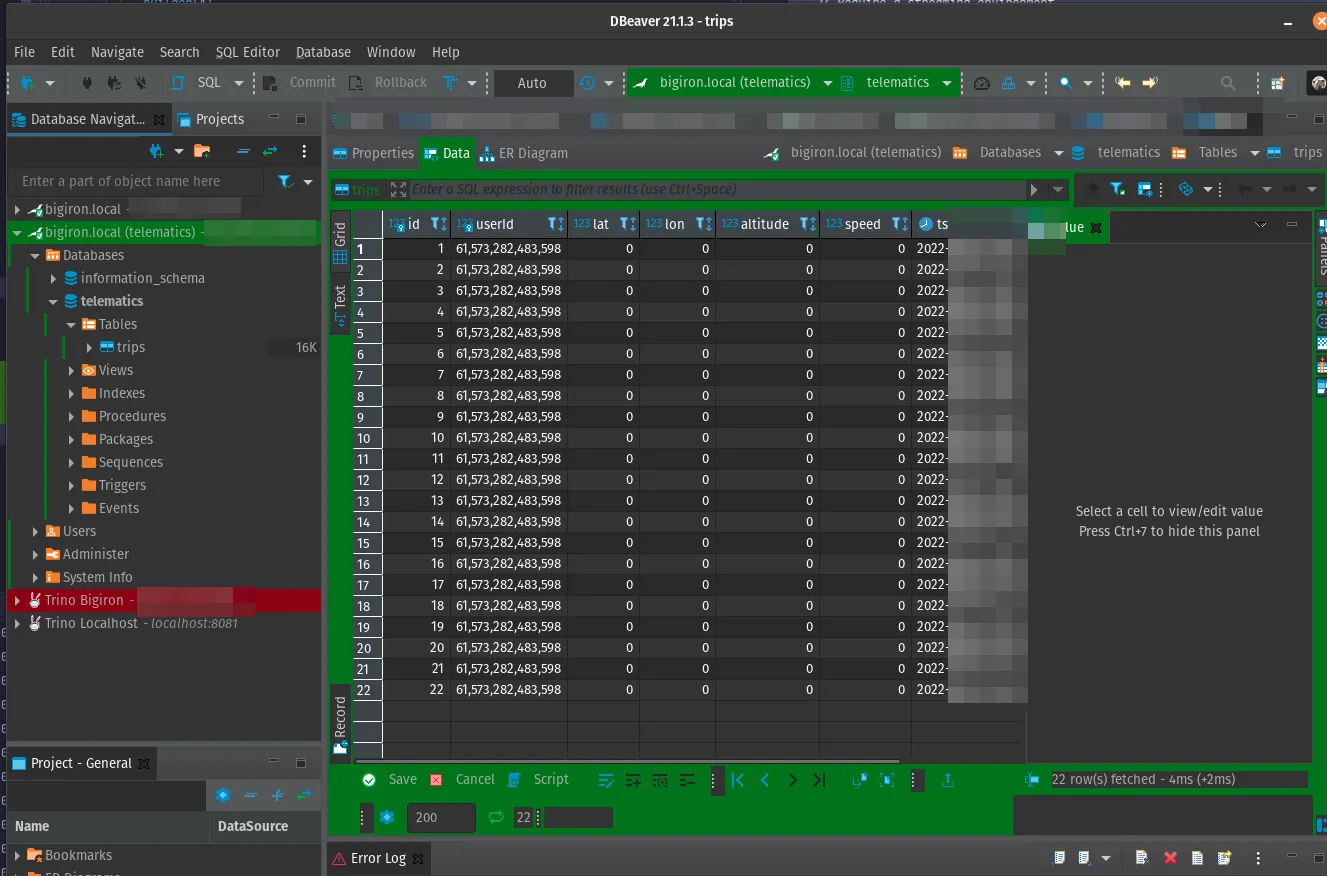
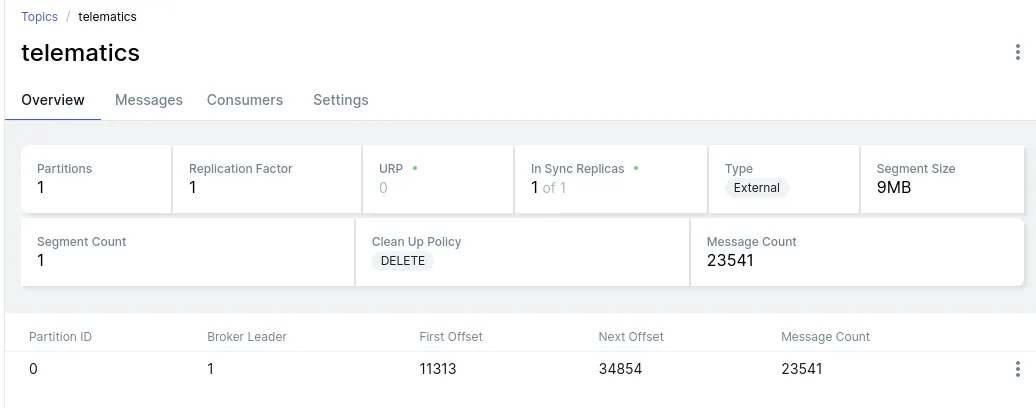
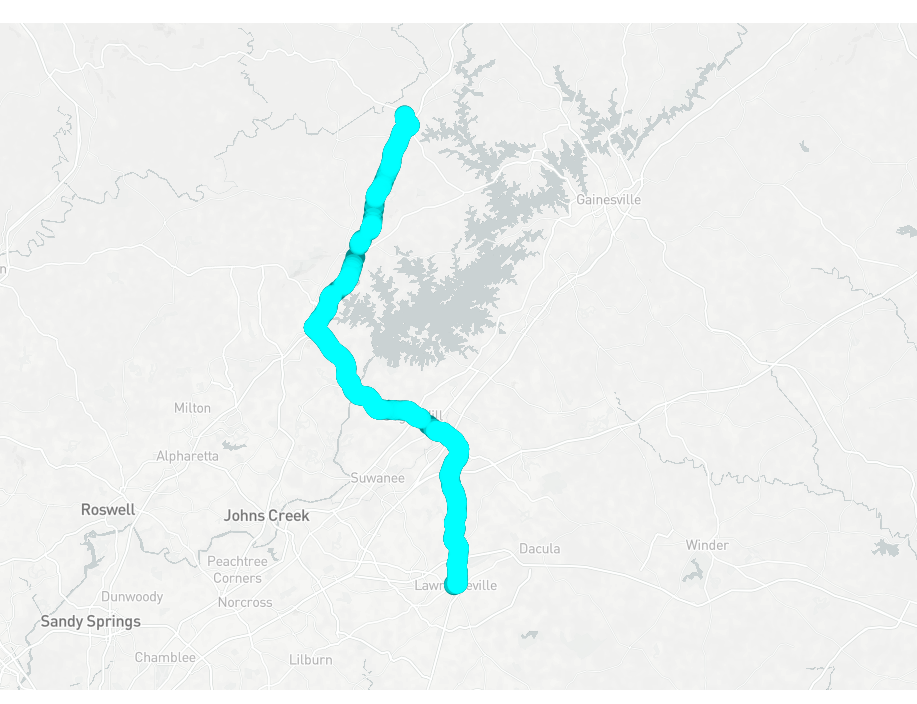
Point being: There should be hundreds of points! Matter of fact, there should be 23,541 points:
However, in sql, let’s ask for “how many points have the exact same location?”:
SELECTCOUNT(*) as C FROMtelematics.tripsGROUP BY lat, lon HAVING lat !=0
ORDER BY C DESC
-- 6028
-- 5192
-- 2640
-- 2200
-- 1885
-- 1356
-- 1320
-- ...
This is the same as before, but worse!
Here’s me walking around the property, staring at debug logs (our neighbors, strangely, still like us…), trying to figure out why on earth the GPS location isn’t changing - as we’ve established before, GPS isn’t super precise, but does go down to 1.11 mm in precision in theory; ergo, walking a couple of feet ought to change my location in the logs, even if only by margin of error, right?
Backyard debugging..
I’ve tried everything - simulated gps data (various formats!), Python 2 style (call next()), Python 3 style (use __next__, i.e. for report in gps_client), printed out the raw (very mutable GpsClient):
Lat/Lon: XXYY# <- real location, but always the same
Altitude: 328.110000
Speed: 0.000000
Track: 0.000000
Status: STATUS_NO_FIX
Mode: MODE_3D
Quality: 4 p=9.41 h=7.40 v=5.81 t=3.49 g=10.03
Y: 18 satellites in view:
PRN: 1 E: 19 Az: 275 Ss: 0#....
Which changes data like satellites every time, but not the location.
Ignore the STATUS_NO_FIX - that’s frequently not reported by the receiver. MODE_3D and 17 satellites in view means it clearly can talk to the mighty sky orbs it so desperately desires.
Turns out: The device I’m using, a u-blox G7020-KT (based on a u-blox 7 chip), so we can use ubxtool to get to the nitty-gritty details:
Terminal window
export UBXOPTS="-P 14"
ubxtool-pMON-VER
#UBX-MON-VER:
# swVersion 1.00 (59842)
# hwVersion 00070000
# extension PROTVER 14.00
# extension GPS;SBAS;GLO;QZSS
This means, we can fine-tune the receiver config. As the physical dongle caches configurations, including previous satellite locks and supported satellite constellations, we can simply reset the entire thing back to default:
Terminal window
# This is important, but depends on your device, see PROTVER above
export UBXOPTS="-P 14"
# Reset configuration to defaults (UBX-CFG-CFG).
ubxtool-pRESET
# Disable sending of the basic binary messages.
ubxtool-dBINARY
# Enabke sending basic NMEA messages. The messages are GBS, GGA, GSA, GGL, GST, GSV, RMC, VTG, and ZDA.
# My reciever can only do basic NMEA0183
ubxtool-eNMEA
# Enable GPS
ubxtool-eGPS
# Save
ubxtoolSAVE
We can then check if everything is in-line with what we expect. The receiver I’m using is fairly primitive (only supports the L1 GPS band and uses a pretty ancient chip), but it can to up to 10Hz (allegedly), but we want the 1Hz default, so it’s a good quick check:
Terminal window
# Poll rate
piubxtool-pCFG-RATE
#UBX-CFG-RATE:
# measRate 1000 navRate 1 timeRef 1 (GPS)
Somehow, somewhere, something changed some physical aspect of my one and only GPS receiver, and that messed up all physical road tests.
Don’t believe me? Real “trip”:
Needless to say, after wasting hours of my life on this - unpaid, of course, because clearly I’m slowly loosing it - it finally worked again.
So… test your hardware, folks. And test the software running your hardware with your actual hardware, do not rely on integration tests.
This is not something I do on the daily. My hardware is in “the cloud” and consists of some Kubernetes nodes somewhere in $BIG_TECH’s datacenters.
I’ve had to debug Kernel problems, network issues, DNS issues, saw UDP used where TCP should have been used, NTP issues, crypto key exchange issues - I’m saying, I’m used to debugging stuff that’s outside of “just debug your code” (I’m sure you’re familiar).
My hardware broken, that happened once and I wrote about it. But a USB dongle (essentially a dumb terminal) being somehow mis-configured, that’s a first for me. You may laugh at me.
[1] Yes, those coordinates represent the Buc-cee’s in Calhoun, GA, and it’s wonderful.
Most GPS points here are either synthetic (thanks to nmeagen.org) or altered as to avoid detailing actual trips for the purpose of this blog article (for obvious privacy reasons). In other words, I probably did not drive straight through some poor guy’s yard in Arlington, GA.
You can find a sample trip here. I’ve converted it to csv and nmeahere and here which ran gpsbabel -w -r -t -i gpx -f "GraphHopper.gpx" -o nmea -F "GraphHopper.nmea". I then piped this data to the TinyTelematics application via gpsfake - everything else was running the real pipeline.
Keep in mind that this data is missing some important attributes, namely speed, altitude, and real, realistic timestamps that would drive many KPIs.
We can use Apache Superset for this. Superset is super cool - it’s a web-based, open source data visualization platform that supports MapBox for geospatial data, who have a very generous free tier.
A Superset Sample Dashboard..
We can set it up via Docker:
Terminal window
gitclonehttps://github.com/apache/superset.git
docker-compose-fdocker-compose-non-dev.ymlpull
docker-compose-fdocker-compose-non-dev.ymlup
Note that for using mapbox, you’ll need to edit docker/.env-non-dev and add your MAPBOX_API_KEY.
Once it’s running, we can add the trips table as a dataset:
(Keep in mind that, while running in docker, superset will try to use your service account from a different IP than your computer, so GRANT ALL PRIVILEGES ON telematics.* TO 'telematics'@'127.0.01'; or similar does not work!)
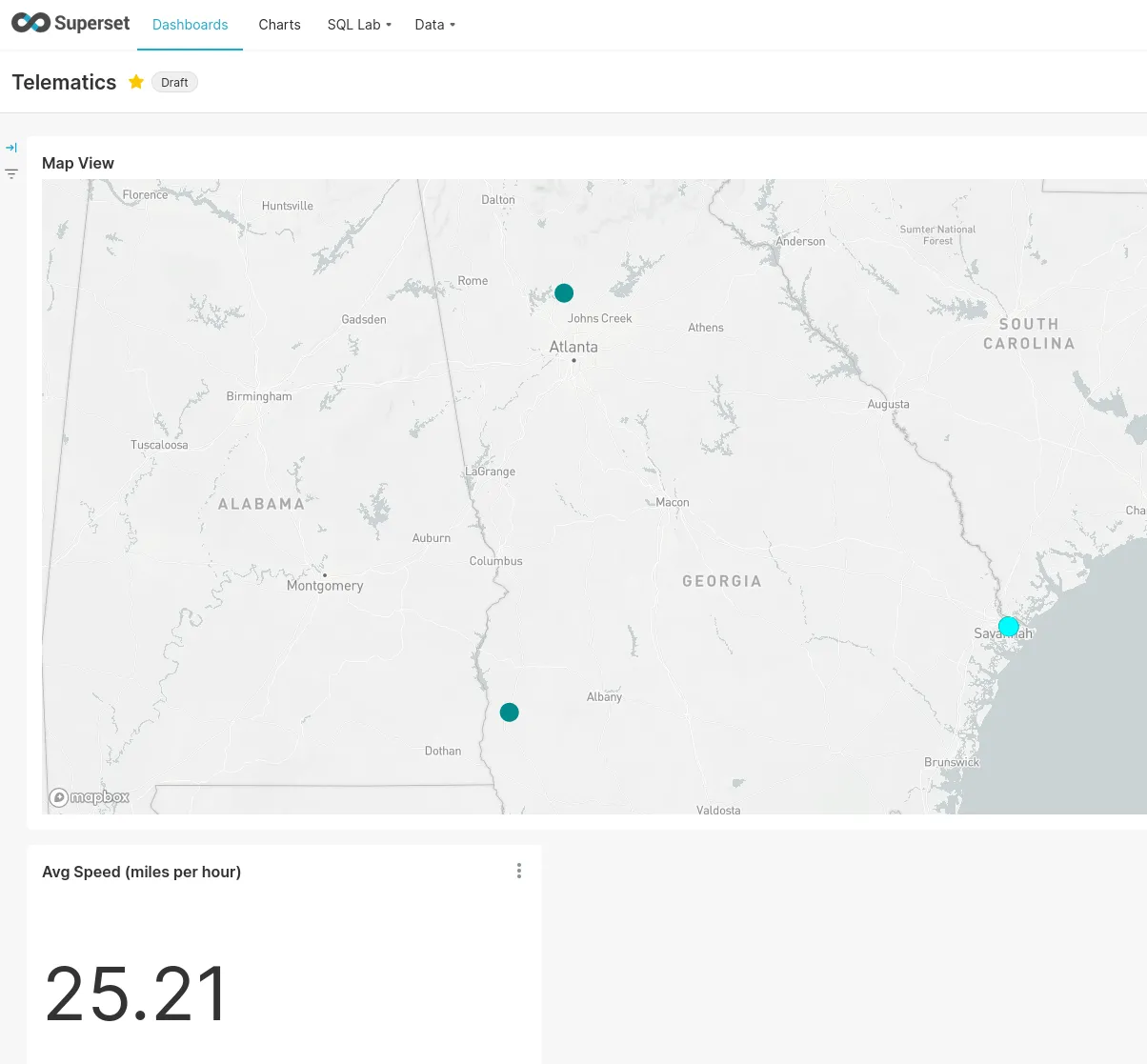
Creating custom charts & a dashboard is also pretty straightforward and my (very basic one) looked like this:
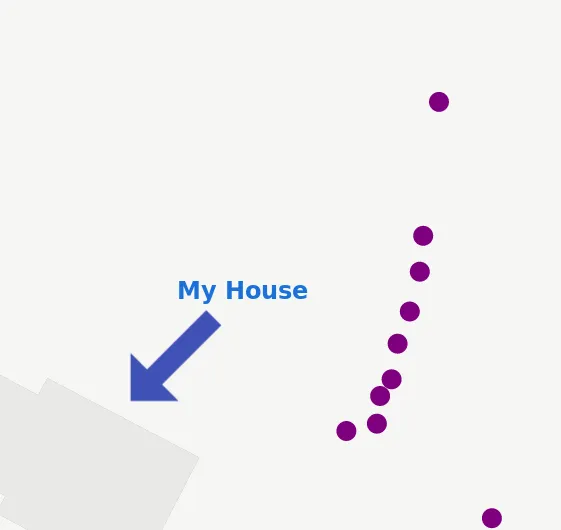
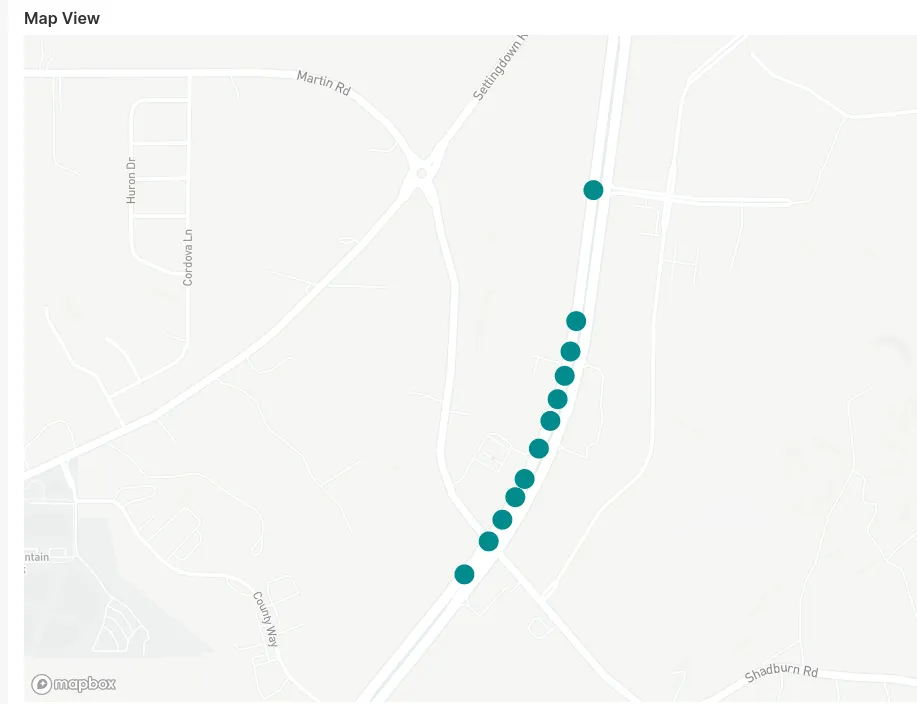
Zooming in on a (synthetic) trip shows individual points:
Note the distance between the points. In this example, the reason for this pattern is simply the way the data has been generated - see below for some thoughts and issues around synthetic testing.
But even with real trips, at a sample rate of 1 sample/s and a speed of 60 miles/hr (or 26.82 meters/s), our measured points would be almost 27 meters or 88 ft apart.
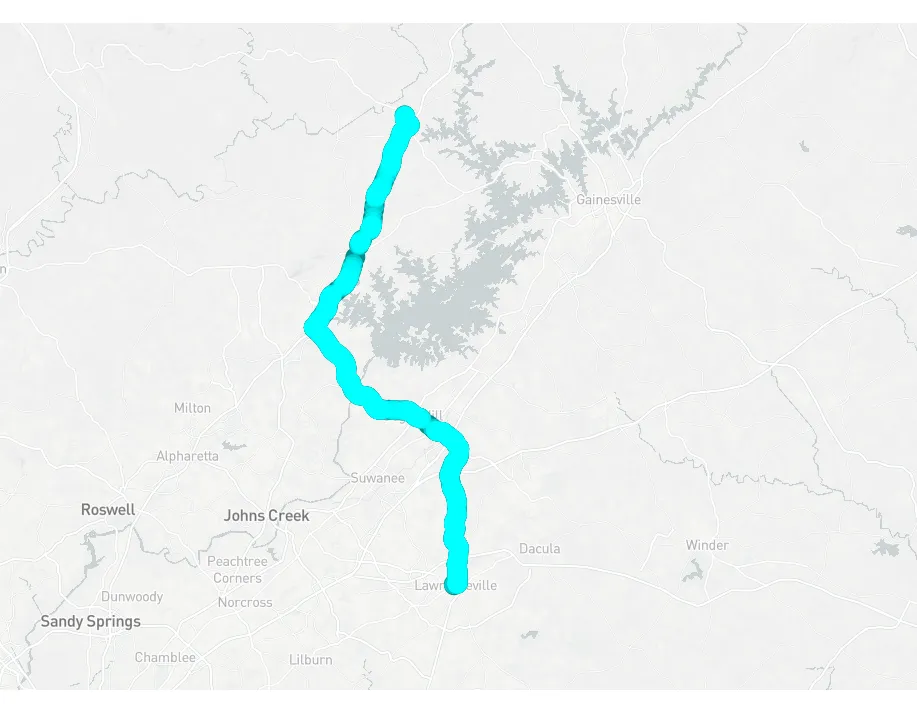
Zoomed out, however, this is a much more coherent trip, even with synthetic data:
The problems with bad sample rates (which can also happen by simply not finding a GPS fix, see “Issues during testing” above!) is that analysis of this data is difficult, even if the zoomed out view (this trip would take about an hour in real life) is certainly coherent.
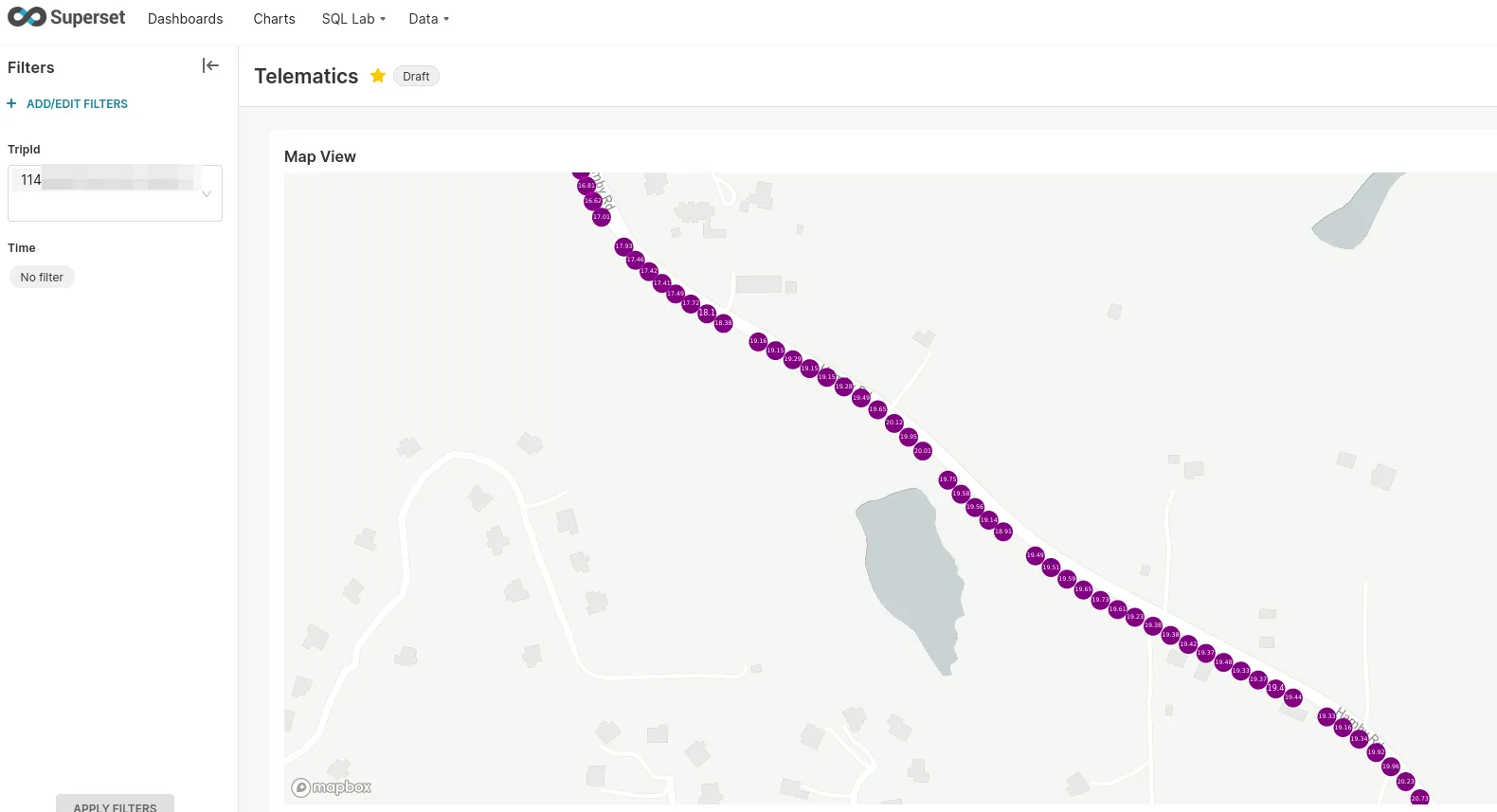
Compare this to the zoomed in view of a real trip collected while driving:
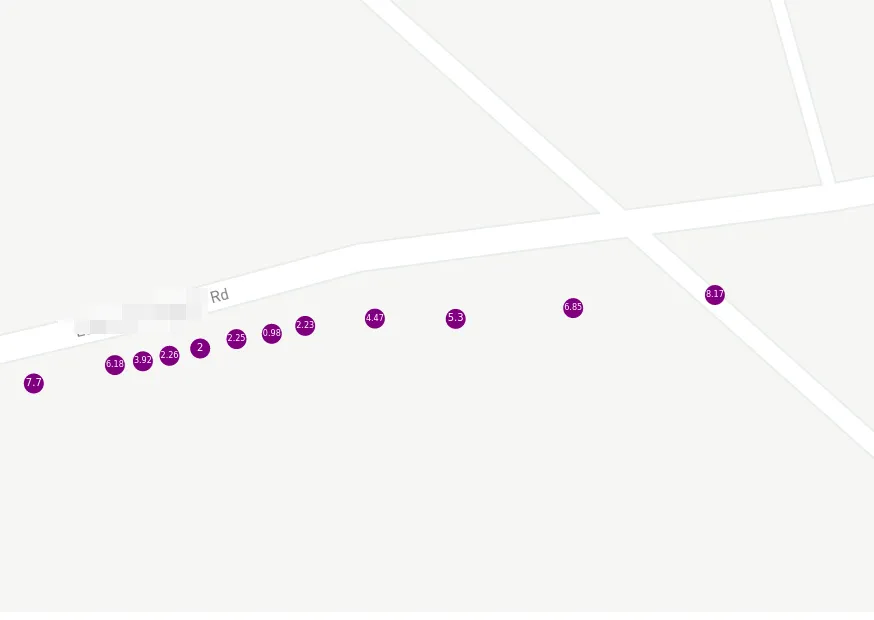
A much more consistent sample rate. However, we can see the GPS precision (or lack thereof) in action once we’re zoomed in real far:
Again, I did not go off-road there. The labels represent speed in meters per second.
However, with this data, we could actually calculate some interesting KPIs via WINDOW functions, such as acceleration or bearing via some trigonometry.
This whole process is eons easier than dealing with (the undoubtedly fantastic!) Python libraries like geopandas or folium. Open source data visualization has come a long way over the years, and not having to know what on earth GeoJSON is is surely helpful to make this more accessible.
However, this particular chart type is missing some of the flexibility e.g. folium would give - it’s great at rendering clusters of points, not such my individual points.
However, we can use the deck.gl Geojson map type and get close-ish to what one does with e.g. folium. Since MySQL (and MariaDB) supports spatial functions, we can add a custom column:
SELECT ST_AsGeoJSON(POINT(lat,lon)) FROMtelematics.trips t
FROM (SELECT*FROMtelematics.tripsORDER BY ts ASC) t
GROUP BY
tripId
)
We then can use this data to render smooth lines:
But cracks are starting to show: In order to color these lines in, you need custom JavaScript and for some reason, it did not take my clearly well formated geojson. But it is possible!
This was a lot harder than I thought it would be and hence, was a fantastic learning-by-doing exercise. I’m decently familiar with all the things I’ve used here, but starting from scratch, including setting up all infrastructure down to the Linux image was an experience.
Just, looking at the code, you’d probably say “That doesn’t look that hard!” - and you’d be right. But as I’ve called out above (and am about to again), the devil’s truly in the tiniest of details here.
The Raspbianiso file while trying to re-size and chroot into it, repeatedly
My spice grinder (that one was unrelated, but it was unreasonably tedious to repair and I’m shaming it publicly here)
The caching logic with redis
java.io.NotSerializableException: Non-serializable lambda in Flink
systemd and gpsd and of course, the combination thereof
Distributed systems such as Kafka and Flink via Docker as single-node instances - much more pleasant than bare metal installs, but annoying for different reasons, especially once you deploy them alongside things like Kafka UI or Kafka Registry or Kafka Registry UI (things I didn’t even write about here, expect for screenshots)
The Mapbox API key for Apache Superset (it’s an environment variable, who knew?)
udev mappings
The Flink TaskManager randomly crashes and I haven’t even read any logs yet
gpsfake with apparmor and myroot access to /dev/pts/
Everything relating to a physical device - see above (I have since purchased a backup device with a different chipset)
Due to all these issues, this was extremely interesting to test. I’ve mentioned synthetic data and integration tests before. We’re probably all used to network and system outages, and that’s why doing something along those lines:
Is so delightful (it fails fast, predictably, and has a type signature to support it). At the very least, we know to throw an Exception and recover from it eventually or at least fail gracefully and try again later. We can even say queryDatabase(query).handleErrorWith(e => ...), since we know from the type that an Exception is a possibility.
In this case, a lot of what is usually good advice just goes out the window.
Once you’re dealing with a system which intentionally is offline, things change quite a bit. A usual strategy of creating & caching an expensive client (say, Kafka) doesn’t work at all, once you realize that you can’t keep that connection alive, since you expect to be offline any time soon. Testing this at home, of course, works well - every time the application is started or debugged, it can talk to Kafka. If it can’t, you automatically assume you broke something.
Also, due to the nature of GPS, testing has to be in-person and on the road, in real conditions - unit and integration tests can only do so much. A quick trip down the road isn’t hard, per se, but it’s much more effort than running a test suite.
The closest I’ve dealt with something like that in the past was an herein unspecified project that used physical RFID scanners and required frequent trips to the midwest and delightful conversations about grain elevators with Uber drivers while there.
“But…!”, I hear you ask. “There’s gpsfake, is there not? Say, does it not open…”
… a pty (pseudo-TTY), launches a gpsd instance that thinks the slave side of the pty is its GNSS device, and repeatedly feeds the contents of one or more test logfiles through the master side to the GNSS receiver.
Note: “Once you need strace, just stop” is usually a more reasonable approach.
And what can even deny root access to run a stupid syscall like sendto(2)? Correct, apparmor and SELinux. (╯°□°)╯︵ ┻━┻
Terminal window
❯sudoapparmor_status
apparmormoduleisloaded.
29profilesareloaded.
27profilesareinenforcemode.
...
/usr/sbin/gpsd
This was one of those things where there’s one mailing list thread from 2012 as a response that doesn’t solve the issue.
> Regressions run just fine here.
Does me no good. :-)
For the record, if you’re here via Google: Just set /usr/sbin/gpsd to complain mode and it’ll work…
Anyways - this is synthetic data. It does not test getting an actual GPS fix in the car, the service starting alongside the vehicle, gpsd talking to the right device, changing WiFi environments, intentional and unintentional network outages, weather conditions, tree canopy and so on and so forth.
You’ve seen some of this data in the previous section - it doesn’t have realistic speeds, altitudes, pauses, traffic conditions etc.
It also, very obviously, did not catch the hardware / configuration issue we’ve dealt with a handful of paragraphs above. Needless to say, it wouldn’t have caught the duplicate record issue neither.
While this was fun (and very usable! Tried it in 2 cars, even!), we really should really be able to…
Write Apache Iceberg instead of plain SQL
Make it actually exactly-once
Generally, do more logic and aggregation in the Flink stream - right now, it’s just a dumb sink
Automatically power the Raspberry on and off (not just the application). This currently happens because my truck cuts USB power after a while, not because it shuts itself down - works in my vehicle, but probably not in yours.
Integrate OBD2 data
Identify trips more consistently
Improve the domain model. It could be much richer
Maybe customize some visualization
Fix some gpsd mishaps and dig deeper and avoid the stupid workarounds
Anyways - I hope you enjoyed it. If you want to try this for yourself, all code is on GitHub as usual.
All development and benchmarking was done under GNU/Linux [PopOS! 22.04 on Kernel 5.18] with 12 Intel i7-9750H vCores @ 4.5Ghz and 32GB RAM on a 2019 System76 Gazelle Laptop, using scala2.12.16

{kind=link}