Blog posts tagged with 'spark''
- Scala, Spark, Books, and Functional Programming: An Essay
2022-02-27: Reviewing 'Essential Scala' and 'Functional Programming Simplified', while explaining why Spark has nothing to do with Scala, and asking why learning Functional Programming is such a pain. A (maybe) productive rant (or an opinionated essay).
scalafunctional programmingoopspark
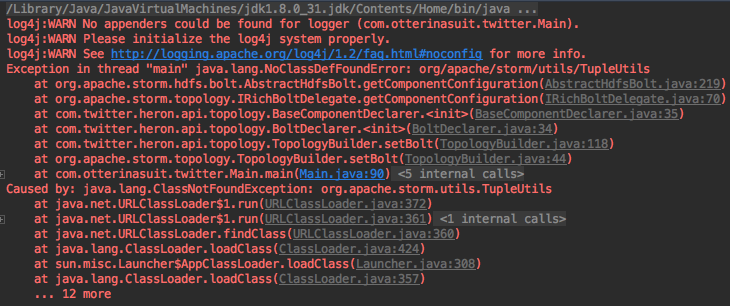
- Building a Data Lake with Spark and Iceberg at Home to over-complicate shopping for a House
2021-12-03: How I build what is essentially a self-service Data Lake at home to narrow down the search area for a new house, instead of using Zillow like a normal person, using Spark, Iceberg, and Python.
scalasparkicebergpythonsqltrinogeopandasbig datahadoophiveprestogeospatial dataanalytics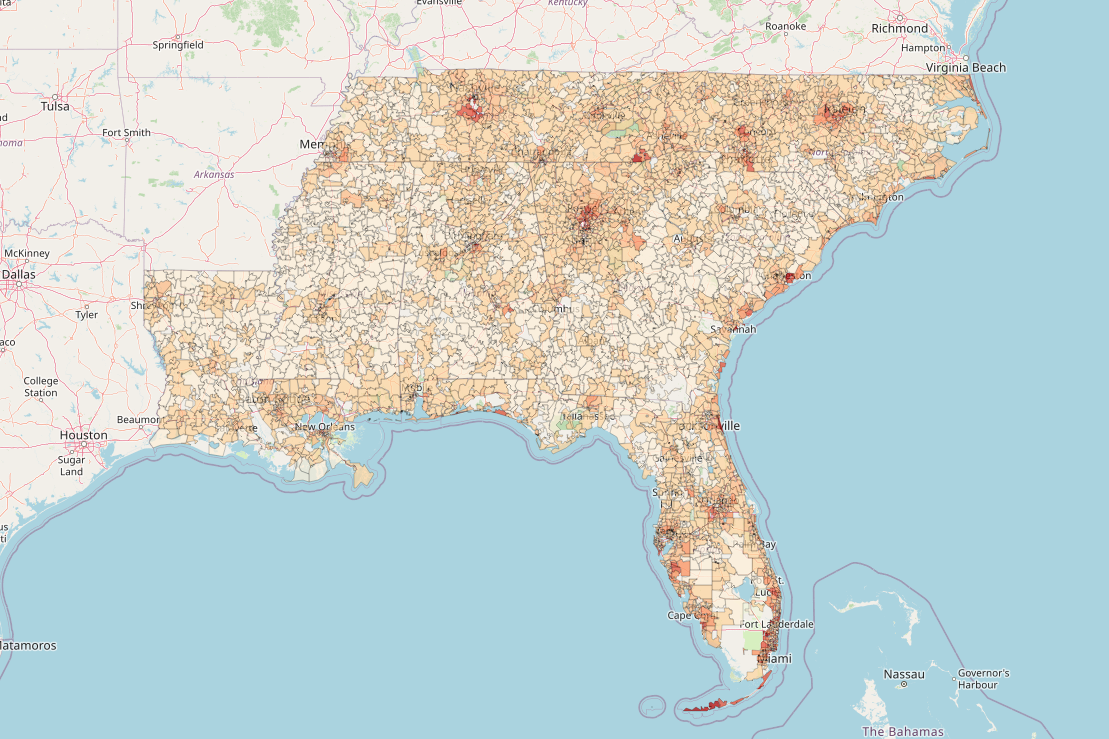
- A Data Engineering Perspective on Go vs. Python (Part 2 - Dataflow)
2020-07-06: In Part 2 of our comparison of Python and go from a Data Engineering perspective, we'll finally take a look at Apache Beam and Google Dataflow and how the go SDK and the Python SDK differ, what drawbacks we're dealing with, how fast it is by running extensive benchmarks, and how feasible it is to make the switch
gogolangpythondataflowbeamgoogle cloudgcpsparkbig dataprogrammingbenchmarkingperformance
- A Data Engineering Perspective on Go vs. Python (Part 1)
2020-06-11: Exploring golang - can we ditch Python for go? And have we finally found a use case for go? Part 1 explores high-level differences between Python and go and gives specific examples on the two languages, aiming to answer the question based on Apache Beam and Google Dataflow as a real-world example.
gogolangpythondataflowbeamsparkbig dataprogramming
- A look at Apache Hadoop in 2019
2019-07-01: In this article, we'll take a look at whether Apache Hadoop still a viable option in 2019, with Cloud driven data processing an analytics on the rise...
awsazurebig datacloudgoogle cloudhivelinuxprogrammingspark
- Data Lakes: Some thoughts on Hadoop, Hive, HBase, and Spark
2017-11-04: This article will talk about how organizations can make use of the wonderful thing that is commonly referred to as “Data Lake” - what constitutes a Data Lake, how probably should (and shouldn’t) use it to gather insights and why evaluating technologies is just as important as understanding your data...
big datahbasehivesparkscalaphoenixdata lakehadoop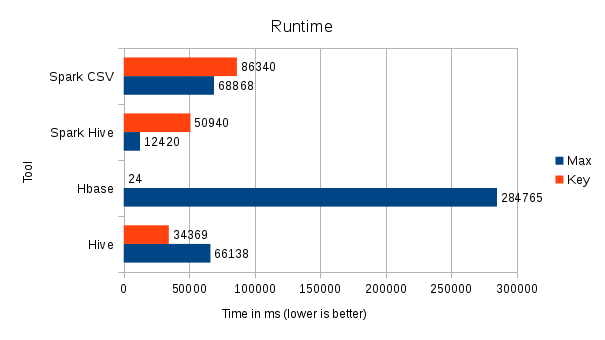
- (Tiny) Telematics with Spark and Zeppelin
2017-03-06: How I made an old Crown Victoria "smart" by using Telematics...
carconnected cartelematicshiveiossparkzeppelinhadoopscala
- Storm vs. Heron – Part 2 – Why Heron? A developer’s view
2016-12-02: This article is part 2 of an upcoming article series, Storm vs. Heron.
big dataheronsparkjavahadoopstorm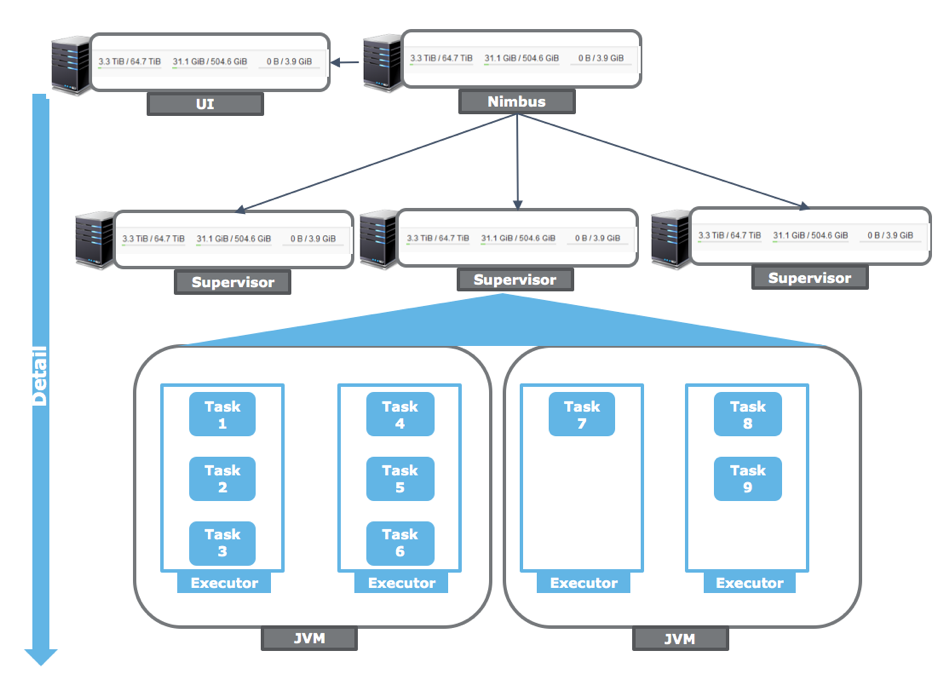
- Storm vs. Heron, Part 1: Reusing a Storm topology for Heron
2016-10-15: This article is part 1 of an upcoming article series, Storm vs. Heron.
big dataheronsparkjavahadoopstorm