Introduction↑
This is an article that’s relatively rough around the edges, somewhat on purpose: It documents my experience, as a Data Engineer, learning “proper” Scala (and Functional Programming), for better or for worse (and what I’ve learned by doing that), why Spark doesn’t count, and why I’m not sure it matters.

Presumably all there is to know about JavaScript vs. the Basics of Scala.
This article is a reflection of a learning process; it doesn’t claim any academic relevance, or even correctness for that matter. If you’re looking for another “What’s a Monad?” article to criticize, this is not the article for you. We’ll talk about a wide range of topics, sometimes explaining them along the way, sometimes not; it is, maybe, indicative of the breadth of the topic as a whole, and the difficulty of approaching it.
Scala’s odd relationship with Data Engineering↑
Let’s start from a common starting point for many folks in the Data Engineering and Data Science space: Most of us will have come in contact with Scala at one point or another - but haven’t actually used the language (bear with me here, folks). I am, of course, talking about Apache Spark, one of the de-facto standards in any self-respecting data stack (and for good reason).
Spark↑
There’s method to my insanity, so hear me out: Spark is written in Scala (more or less), and you obviously use the language to write Spark jobs. What you don’t do, though, is write idiomatic Scala - you barely write functional code to begin with.
Let’s take a step back and take a look at how a standard Spark program looks like (shortened for brevity, but otherwise straight from the offical docs):
val file = spark.read.text(args(0)).rddval mapped = file.map(s => s.length).cache()for (iter <- 1 to 10) { timer({for (x <- mapped) { x + 2 }},iter)}println(s"File contents: ${file.map(_.toString).take(1).mkString(",").slice(0, 10)}")println(s"Returned length(s) of: ${file.map(_.length).sum().toString}")It’s relatively straightforward:
- Ln 1: You read a text file into an
RDD, an immutable (and distributed), basic dataset - Ln 2: You evaluate an anonymous function on each element of the resulting dataset, mapping a thing of
sto it’s length (it’s not clear from the example, but most likely, aString); ignore thecache()part for now - Ln 3-5: Start a for loop, run the same function 10 times, print the runtime; (Slightly altered to remove the timer block) [1]
- Ln 6-7: Print some metrics from the file(s)
But it’s still Scala code - just not very idiomatic.
[1] For those who care:
def timer[A](f: => Unit, iter: Int): Unit = { val startTimeNs = System.nanoTime() f val durationMs = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startTimeNs) println(s"Iteration $iter took $durationMs ms")}Functional Programming Tenants↑
Without meaning to give a full introduction into the topic - see Wikipedia for that - here’s what I mean when I talk about functional programming.
The general idea behind the paradigm is best summed up as follows:
We believe in the separation of Church and state!
Which is a not-so-clever play on Alonzo Church, the guy who came up with Lambda calculus, which has no mutable state by design.
Or, if beaten-to-death jokes aren’t your jam, maybe this serves you better:
Haskell is a purely functional programming language. In imperative languages you get things done by giving the computer a sequence of tasks and then it executes them. While executing them, it can change state.
For instance, you set variable a to 5 and then do some stuff and then set it to something else. You have control flow structures for doing some action several times.
In purely functional programming you don’t tell the computer what to do as such but rather you tell it what stuff is. […] You also can’t set
avariable to something and then set it to something else later. If you say that a is 5, you can’t say it’s something else later because you just said it was 5. What are you, some kind of liar?So in purely functional languages, a function has no side-effects. The only thing a function can do is calculate something and return it as a result. At first, this seems kind of limiting but it actually has some very nice consequences: if a function is called twice with the same parameters, it’s guaranteed to return the same result. That’s called referential transparency and not only does it allow the compiler to reason about the program’s behavior, but it also allows you to easily deduce (and even prove) that a function is correct and then build more complex functions by gluing simple functions together.
From: “Learn You a Haskell for Great Good!”, by Miran Lipovača
Haskell is, arguably, is one of the purest functional programming languages (it is named after Haskell Curry, at the end of the day), and its design philosophy reflects that.

(Credit: Credit: Alvin Alexander)
Scala is not Haskell↑
Scala, on the other hand, is a bit of a mixed bag: Its running on top of the JVM, so it can’t really stop you from writing OOP-code that mutates state left and right, but it doesn’t try to: It allows you to write object-oriented, imperative code if you so desire; matter of fact, all three of these code blocks:
def sum1(l: List[Int]): Int = { var i = 0 var s = 0 while(i < l.size){ s += l(i) i += 1 } s}
import scala.annotation.tailrec@tailrecdef sum2(l: List[Int], s: Int = 0): Int = l match { case Nil => s case _ => sum2(l.tail, s+l.head)}
def sum3(l: List[Int]): Int = l.foldLeft(0)((a,b) => a+b)Are, for all intents and purposes, identical:
l = List(1, 2, 3)
sum1: (l: List[Int])Intsum2: (l: List[Int], s: Int)Intsum3: (l: List[Int])Int
666So, why care?
Data Engineering’s Friends: Type Safety & Deterministic Functions↑
I’ve talked about this before, at length, in A Data Engineering Perspective on Go vs. Python (Part 1) in June of 2020, so I’ll sum it up real quick:
- We work a lot with data (duh). Type safety, ideally static typing and a compiler who cares (and warns us), is a helpful companion.
- Dynamically typed languages have a place, but relying on type hints make it difficult to deal with systems that have static schemas, such as databases.
- While at the same time, providing benefits for systems with loosely-schematized data (Note: I hate the word “schemaless”, because it means nothing).
- We almost exclusively design, write, and maintain backend systems; these systems are run by robots, talk to robots, and often have pretty aggressive SLAs; they need to be stable, scalable, and hands-off.
- We deal with sensitive data; our output must to be deterministic. Some people argue our systems should be transactional, but I disagree; at the very least, we need to make sure not to alter any meaning of the data we work with; sometimes, this can even be illegal.
- Our process will never be deterministic because we are dealing with distributed systems; designing distributed systems that behave deterministically are often incompatible with high scalability requirements (e.g. single-leader systems with no resilience in the followers, such as a replicated database, can behave deterministically in certain situations).
- Finally, we need an ecosystem of tools, libraries, and people that support our use cases
If we look at those desires, functional languages all of a sudden offer a lot of benefits:
- Pure functions (or as the mathematicians say, “functions”), are deterministic by nature; the nerds call it “referential transparency”, which is a broader concept
- Referential transparency can only be achieved by typing things correctly;
f1: A => Bcan be replaced withf2: A => B, but never withf3: A => C; this doesn’t argue about the internal algorithm off1orf2, but based on their signatures, they are interchangable - Immutable values are useful:
a = f(x)andb = g(a)can be expressed asg(f(x)), just like in regular algebra; this is only possible because mathematicians would never dream of writinga = f(x); a = a + 1; b = g(a). If you treat your program like algebra, immutability of variables becomes natural - In the same vein, so does idempotency; no sane mathematician would entertain the thought of
f(x)mutating anything (it’s a stateless system) - Semi-realted-but-important, if you look at it like algebra,
nullmakes no sense of all a sudden, and neither does the idea of anException[1]
Of course, we can also about the beaten-to-death, theoretical benefits functional programming is supposed to offer; but I find that so tedious that I added a joke about Haskell in the randomized footers of this blog you’re reading right now in May of 2020. [2]
# Stupid footers :) footers = [ "Haskell: A 70 Page Essay on why it will be the Next Big Thing - this Time for real!" // .. ][1] go, despite not being functional, follows this mantra, which i praised in the article I linked above.
[2] The irony of this is not lost on me.
Back To Spark↑
Okay, so, on paper, ideas taken from functional programming are useful for Data Engineering (we haven’t argued about I/O yet, so bare with me once again). So why are we saying that “Learning Spark” != “Learning Scala”?
Types↑
Let’s actually add types (as we just discussed, a core, overlapping principle between DE and FP) to our example from before and ignore that for loop for a second:
val fileName: String = "data/test.txt"val file: RDD[Row] = spark.read.text(fileName).rddval mapped: RDD[Int] = file.map(s => s.length).cache()This RDD takes a type parameter, T (already not idiomatic Scala, but I digress):
abstract class RDD[T: ClassTag](@transient private var _sc: SparkContext, @transient private var deps: Seq[Dependency[_]]) extends Serializable with LoggingSparkContext and deps are @transient, which means they’re not copied on serialization, which is a topic I’m sure many Spark developers are intimately familiar with, and I’m willing to ignore that whole rabbit hole for now. I’m also willing to ignore that this has a side-effect: sc throws an Exception in certain cases. In Java-land, this is normal; I won’t argue against it for now, because a Spark program needs a SparkContext, and the difference between the JVM imploding before it even starts and you having to call exit(1) is miniscule.
…but a clear type signature nonetheless. Once we start breaking down the individual steps, however, things don’t look as pretty:
val fileName: String = "data/test.txt"val f1: DataFrameReader = spark.readval f2: DataFrame = f1.text(fileName)val f3: RDD[Row] = f2.rddval mapped: RDD[Int] = f3.map(s => s.length)val mapped2: mapped.type = mapped.cache()This, all of a sudden, looks a lot less rosy: f2, the DataFrame, is defined as:
type DataFrame = Dataset[Row]And a Row is a
trait Row extends Serializable // ...def apply(i: Int): Any = get(i)def get(i: Int): AnyAny is not really a type in any (heh) language - it’s a catch-all.
Line 5 brings things back to reality (and out of the abstractions we’re not supposed to see), though: RDD[Row] turns into RDD[Int].
map, flatMap, and for expressions↑
And that’s thanks to the map function: In Scala, a Functor (“a design pattern inspired by the definition from category theory, that allows for a generic type to apply a function inside without changing the structure of the generic type” [1]) looks like this:
trait Functor[F[_]] { def map[A,B](a: F[A])(f: A => B): F[B]}In Spark, map is implemented as follows:
/** * Return a new RDD by applying a function to all elements of this RDD. */def map[U: ClassTag](f: T => U): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))}And, since we’re at it, also implements flatMap:
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope { val cleanF = sc.clean(f) new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.flatMap(cleanF))}In functional programming land, implementing map and flatMap (and filter, which RDD does) allows the use of for comprehensions or (for expressions), which are not to be confused with for loops. So, does this work?
val l = for { f <- mapped //generator v = f * 2} yield (v)println(s"For expression: $l")Sure does work. But what does the last statement print? Well, nothing useful of course, because this statement is equivalent to:
val l: RDD[Int] = mapped .map { f => val v = f * 2; (f, v) } .map { case (f, v) => (v) }And Spark evaluates stuff lazily once needed.
Which is to say, thus far, this Spark code does behave in a nice and “functionally-adjacent” manner:
- We have types & bounds; at least on the surface, they’re clear. Somebody might argue that’s all a developer needs to care about, and I think there’s an argument to be made there
- Our variables are immutable
map,flatMap, andfilterare present and I can use higher order functions,forexpressions, and other “functional” tidbits if I so desire; those functions should be pure as well (f: Int => Int = _*2, as used above, certainly is)
But one thing is really off, even while being generous and ignoring the weird type changes, the lack of Scala-like typing (no type bounds, no higher-kinded types), and the throwing of Exceptions, and that’s the root of all evil of about half the stuff I outlined above: I/O.
Everything in Spark is IO↑
Distributed Systems, such as Spark, do (practically) everything as I/O eventually: The system will always get an input from a non-deterministic source; nothing guarantees me that spark.read.text(fn) returns the same file every time I call it (because the file can change, and that’s outside our control). This is true for both standalone and distributed deployments.
In most cases, there will be data sent over the network; a call such as map(_*2) simply tells Spark to execute this operation on each element of the dataset; it doesn’t tell you where that will happen. In a sense, I would argue that the Spark dialect of Scala is in many aspects closer to a declarative than to an imperative language because of that.
In any case, the calculation of x*2 itself may be a pure function on each of its invocations; however, the overall system is a system comprised of side-effects. I won’t go into much more detail as to why I believe that to be true - the wealth of Distributed Systems literature backs my thought in many thousands of pages. We’ll talk about if this is even relevant at the end of the day a little further down.
Coming back to our dissected example above:
val fileName: String = "data/test.txt"val f1: DataFrameReader = spark.readval f2: DataFrame = f1.text(fileName)val f3: RDD[Row] = f2.rddval mapped: RDD[Int] = f3.map(s => s.length)val mapped2: mapped.type = mapped.cache()Line 6, may look like this:
def cache(): this.type = persist()But if the type signature was honest with us, it should really look like this (but would make for a much crappier interface):
def cache(): IO[Unit]IO here is the dreaded “Monad”:
A monad is a mechanism for sequencing computations. […] Monadic behaviour is formally captured in two operations:
pure, of typeA => F[A];flatMap, of type(F[A], A => F[B]) => F[B].From: “Scala With Cats”, by Noel Welsh & Dave Gurnell
Or, perhaps more realistic view:
The trick of the IO monad is that it lets you write I/O functions as effects. Philosophically, what happens is that you use I0 to describe how an I/O function works. Then, instead of dealing with the result of the I/O function at the time when the I/O function appears to be called, you defer the actual action until some time later when you really want it to be triggered.
From “Functional Programming, Simplified”, by Alvin Alexander
And, of course:
The
IOmonad does not make a function pure. It just makes it obvious that it’s impure.Martin Odersky
In other words: If you’re doing super-obvious I/O, at least tell me, so I can at least describe an action and deal with effects. Spark abstracts this from the developer, but does essentially that: It lets you write logic, but deals with the effects by simply only guaranteeing eventual consistency and atomic behavior for writing output; in other words, you don’t really care if something fails: If you adhere to the Spark framework, your maps, flatMaps, groupBys (…) are all pure, but the entire Spark job may as well fail. This is, in essence, not to dissimilar from SQL, which brings me back to my point of Spark being a declarative language, rather than Scala dialect.
But back to my point that “Learning Scala” != “Learning Spark”: In cats-effect (to use something probably more idiomatic to pure Scala), you’d deal with actual, visible IO via flatMap, just like any other Monad:
A value of type
IO[A]is a computation which, when evaluated, can perform effects before returning a value of typeA.
IOvalues are pure [sic, see above], immutable values and thus preserves referential transparency, being usable in functional programming. AnIOis a data structure that represents just a description of a side effectful computation. IO can describe synchronous or asynchronous computations that:
- on evaluation yield exactly one result
- can end in either success or failure and in case of failure flatMap chains get short-circuited (IO implementing the algebra of MonadError)
- can be canceled, but note this capability relies on the user to provide cancellation logic
More quotes from the docs make this clearer:
First of all we must code the function that copies the content from a file to another file. The function takes the source and destination files as parameters. But this is functional programming!
So invoking the function shall not copy anything, instead it will return an
IOinstance that encapsulates all the side effects involved (opening/closing files, reading/writing content), that way purity is kept. Only when that IO instance is evaluated all those side-effectful actions will be run.
override def run(args: List[String]): IO[ExitCode] = for { _ <- if (args.length < 2) IO.raiseError(new IllegalArgumentException("Need origin and destination files")) else IO.unit orig = new File(args.head) dest = new File(args.tail.head) count <- copy(orig, dest) _ <- IO(println(s"$count bytes copied from ${orig.getPath} to ${dest.getPath}")) } yield ExitCode.SuccessThe details on how cats-effect does it doesn’t really matter (and I’m only at the beginning of the cited book above myself, so I wouldn’t even really know :) ), but one point still stands: This is a very different way of abstracting I/O than Spark does it and, arguably, much closer to a language like Haskell, from here Scala got its for expression syntax
It’s really not the same thing↑
So I’m hoping I made a point here: Just because you (or I) used Spark extensively, unless we learned it elsewhere, we know nothing about Scala. For me, that was a bit of a hard pill to swallow; but ultimately, I find it to be true. Too much in Spark is abstracted away, and too little follows standard functional patterns, even though the bones are there.
If you, personally, can benefit from a more functional style in DE work - or even look at Spark from a more functional lens - that I can’t tell you. But I will try to shed some light on my thoughts in the second half of this article.

(Credit: Credit: xkcd 1270)
In normal Software Engineering↑
Outside of Spark, Scala looks very different (at least in my opinion) - and behaves very differently.
Case Study: An Immutable Tree↑
Let me start this off with a bit of code. Take a minute and see if you can explain what’s going on here and, more importantly, why:
package com.chollinger.scala
import cats.effect.{ExitCode, IO, IOApp}
import scala.language.implicitConversions
object Main extends IOApp { def run(args: List[String]): IO[ExitCode] = IO({ println(BST[Int](2).put(7).put(6).put(5).put(9).has(7)) println(BST[Int](2).put(7).put(6).put(5).put(9).map(_ * 2).has(7)) }).as(ExitCode(0))}
sealed trait Tree[A] { def put(v: A): Tree[A] def has(v: A): Boolean def get(v: A): Option[A] def map[B](f: A => B)(implicit a: Ordering[B]): Tree[B]}
case class EmptyBST[A]()(implicit a: Ordering[A]) extends Tree[A] { override def put(v: A): Tree[A] = BST(v, this, this) override def has(v: A): Boolean = false override def get(v: A): Option[A] = None override def map[B](f: A => B)(implicit a: Ordering[B]): Tree[B] = EmptyBST[B]()}
case class BST[A](value: A, left: Tree[A], right: Tree[A])(implicit a: Ordering[A]) extends Tree[A] { override def put(v: A): Tree[A] = v match { case _ if a.compare(value, v) == 0 => BST(v, left, right) case _ if a.compare(value, v) > 0 => BST(value, left.put(v), right) case _ if a.compare(value, v) < 0 => BST(value, left, right.put(v)) }
override def get(v: A): Option[A] = v match { case _ if a.compare(value, v) == 0 => Some(this.value) case _ if a.compare(value, v) > 0 => left.get(v) case _ if a.compare(value, v) < 0 => right.get(v) case _ => None }
override def has(v: A): Boolean = get(v) match { case Some(_) => true case None => false }
override def map[B](f: A => B)(implicit a: Ordering[B]): Tree[B] = BST(f(value), left.map(f), right.map(f))}
object BST { def apply[A](value: A)(implicit a: Ordering[A]): Tree[A] = EmptyBST[A]()(a).put(value)}What this is is relatively straightforward: A non-rooted, non-balanced binary search tree, or BST, sans a delete method, since we’re not talking about BST, but rather about the language; the deletion and re-balancing algorithms in basic trees are irrelevant here.
Why it looks the way it does is a separate question entirely. Allow me to unload the buzzwords: The implementation is immutable, therefore recursive (but not tail-recursive), uses only pure functions, a basic version of algebraic data types (ADTs), bastardized pattern matching, implicits (maybe a type class, not even sure), higher-order functions, technically F-bounded polymorphism (because view bounds or <% are the equivalent to having an implicit conversion available), companion objects, and parameter groups.
For the sake of completeness, it also contains both implementations of Functors and (technically) Monads, both equally useless fluffy filler-words in this example.
The reason why I used this example is not because an unbalanced BST is in any way shape or form useful outside of figuring out B+ -Trees; [1] I’ve written this to illustrate a point: This does not look like Spark code.
Even worse, I wrote this. I started learning Scala maybe a month ago (not counting Spark, see above), and examples from real libraries such as cats or Akka look outright horrifying to the untrained eye:
def transmit[F[_]: Sync](origin: InputStream, destination: OutputStream, buffer: Array[Byte], acc: Long): F[Long] = for { amount <- Sync[F].delay(origin.read(buffer, 0, buffer.length)) count <- if(amount > -1) Sync[F].delay(destination.write(buffer, 0, amount)) >> transmit(origin, destination, buffer, acc + amount) else Sync[F].pure(acc) // End of read stream reached (by java.io.InputStream contract), nothing to write } yield count // Returns the actual amount of bytes transmitted[1] I believe there is a paper floating around that explains why recursive trees are, generally speaking, a terrible idea, and why mutable state isn’t that terrible; I picked this example out of some sort of academic masochism.
Learning Scala like you learn Algos & DS↑
Allow me to take a step back: These past 4 or so months, I’ve read quite a lot of literature semi-related to my job as a Data Engineer: Robert Sedgewick’s Algorithm Course @ Princeton [1] with Steven Skiena’s “The Algorithm Design Manual” for written details on the material covered in the course [2], and Martin Kleppmann’s “Designing Data Intensive Applications” [3], especially the latter of course being well-beloved by other Data Engineers. A lot of the content wasn’t necessarily brand new to me, but I felt in need of a refresher - mostly for my own curiosity. I’ve yet to implement a Hash Table from scratch (although I did it for fun), but you never know. I never went to grad school, so I had to teach myself a lot of stuff, and so learning from proper smart people is a good plan every once in a while. :)
More recently, I’ve taken to properly learning Scala using the same approach - which is not something I’d usually do for a programming language, but rather something reserved for the classroom. The big difference to the other topics in the paragraph above: I did this because it appeared to be the only way to tackle the topic properly.
Books vs. The Internet↑
The reason why I am, generally, not a big fan of programming books is twofold: First of, most of them are out of date by the time they’re printed, at least with more in-flux languages. Second of all (and more importantly), most of them are, simply put, mostly the same. go’s Wikipedia article, for instance, is deceptively short; it mainly lists language features and gives some examples:
Gois a statically typed, compiled programming language designed at Google by Robert Griesemer, Rob Pike, and Ken Thompson.Gois syntactically similar to C, but with memory safety, garbage collection, structural typing, and CSP-style concurrency.
If you’ve been around programming for a bit, none of those terms should be a big surprise; as a matter of fact, Wikipedia also has this interesting “Comparison of programming languages” article that simply checks boxes for Imperative, OOP, Functional, Procedural, Generic, Reflective, and Event-Driven.
Scala, by the way, checks all those boxes, except for Procedural, Java and Python check all of them, including “Functional”. There is a finite set of things you can explain in a book, without re-explaining the concept of a variable or a method.
Of course, if you have no idea what “OOP” is, you’d probably want a book, or at the very least, a great set of articles on it; but Scala (as a JVM language) falls under OOP. So what makes it, at least for me, so different?
Learning “FP” in Python without a Book↑
As I’ve outlined above, the term “Functional Programming” is a bit loaded; if you’d asked me a couple of months ago what “real world” functional programming - i.e. in code people write for production - looks like, I’d told you this is as far as it goes:
list(map(lambda x: x*2, [1,2,3]))[2, 4, 6]This is Python, if it isn’t obvious, and it’s using a map (a “Functor”) on a collection of elements, by means of passing a function, which makes this technically a higher-order function (the same can be said about list()). I’ve maybe talked about currying a bit in the context of Python, and recursion at the edge of what I would even describe as “functional-only” specifications.
Python, fun fact, actually has a lot more functional (or, at least, functionally inspired) stuff baked in: Python 3.10 even got structural pattern matching. Ironically, the example in the PEP specification uses non-deterministic input as an example: [1]
command = input("What are you doing next? ")match command.split(): case [action]: ... # interpret single-verb action case [action, obj]: ... # interpret action, objWhich, if you ask me, isn’t very functional - in Scala, you use pattern matching all the time.
Python is not the topic of discussion here, though: It’s the fact that Python might support all this stuff, but it’s really an afterthought, and, more importantly, the language doesn’t lend itself to even remotely providing the benefits of FP I outlined above, not the mention the ones academic literature regurgitates year after year (Easier concurrency & parallelism! Easier Debugging! Faster Development Cycles! etc).
And for the record, I like Python, but is this a pure function?
def add(x: int, y: int) -> int: return x + yThe answer is, technically, a “yes”, because while you can do this (1.2 is a float):
>>> add(1,1.2)2.2It still doesn’t mutate state.
However, Python also has no (real) notion of immutable variables; while primitives are actually immutable, this here is still perfectly valid:
>>> x: int = 5>>> x5>>> x = lambda x: print(x)>>> x<function <lambda> at 0x7fd16b159a60>>>> x('5')5Just because
>>> def inc(x: int) -> int:... x = x + 1... return x...>>> x = 5>>> inc(x)6>>> x5Doesn’t automatically have a side effect (x is still 5), Python lacks a val (or final) keyword and the most common data types (dicts, lists, classes) are all mutable by default.
So, just because you can “do FP” (and see it being done - usefully I might add, because lambda expressions are used heavily these days), it doesn’t cause existential that learning Scala does (I originally learned Python mostly for fun, on the side, by messing around with it). So what is it?
The Lingo & The Teachers↑
The obvious answer to the question is the following: “You just happen to know OOP, that surely wasn’t easy to learn, so you just assume that to be the default”.
And, to a large degree, yes, that is correct; OOP is the default for many people. Here’s an overview from 2014:
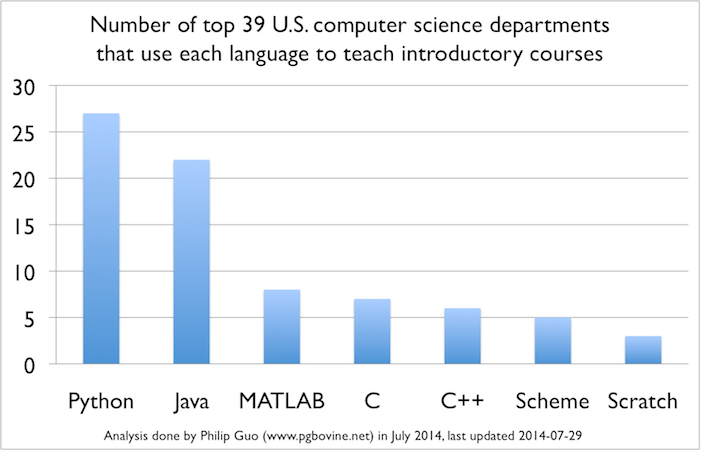
(Credit: Credit: Philip Guo)
More recent data from StackOverflow has JavaScript + Typescript, Python, Java, C#, and C++ in the Top 10 most popular languages for professional developers. If I skip the outliers (non-languages and frameworks, e.g. HTML/CSS or node.js or declarative languages such as SQL), I barely get C, are purely procedural language, in the Top 10. I think it is fair to assume that yes, OOP is indeed a bit of a standard. [1]
If this is correct or not, that is up for debate; but coming back to OOP, the lingo to adequately convey thoughts in OOP is pretty finite, barring super obscure context like type bounds or prototype-things (the author has vague memories of JavaScript): Classes, Objects, Polymorphism/Inheritance, Class/Instance/Member variables, static keywords, Interfaces, abstract classes, and this list even has a bit of a Java bias, because that was my first OOP language.
So what makes FP so hard to approach? I think this picture from Alvin Alexander, who’s book I’ll review in a second, sums it up beautifully:

Books. The man has books..
(Credit: Credit: Alvin Alexander)
Functional Programming has both a language barrier, as well as problem with overly-academic approaches to teaching it.
Imagine yourself back in college (or wherever you first learned about programming), and some weird-looking man started rambling on about Category Theory (to this day, I do not know what that is, and I don’t care to find out), Functors, Monads, Higher-Kinded Types, Algebraic Data Types, Currying, and why the other side is stupid anyways.
All the while your friendly OOP beginner class tells you “Well, see, a Dog is an animal, I guess we can all agree? Cool, so let’s say a Cat is also an animal, right? Here’s pictures of my pets by the way… anyways… yes, yes, they’re adorable… anyways, both, generally speaking, “do stuff” and “have stuff”. For instance both might have a favorite food: …” (and so on and so forth - by far the most common way I’ve heard OOP explained). Naturally, the OOP example can be more academic, but with very little prior knowledge, I can explain the benefit of OOP - abstraction and reusability, for instance - very easily. I can’t do this with FP.
So, the problem, in my unimportant opinion, is as follows: The benefits of FP are completely lost on anyone who hasn’t already got a whole bunch of programming experience under their belt (change my mind). There are, undoubtedly, the more academically-minded folks who are just into that sort of stuff and view FP as a logical extension of their many math classes; for instance, they might argue that since a function evaluates to a result, using a keyword such as return is blasphemy.
But I dare to say that for most of us, programming is a means to an end: We build stuff. In my line of work, we build cool distributed systems that move data around so that other people run clever math on them and build pretty graphs. For this crowd, the bombardment with terms and the lack of “Why would I care?” is overwhelming.
Coming back to Spark for a wee second: Here’s a quote from a book about the topic.
A
Monoidextends aSemigroupby adding an identity or “zero” element…
In big data applications like
SparkandHadoopwe distribute data analysis over many machines, giving fault tolerance and scalability. This means each machine will return results over a portion of the data, and we must then combine these results to get our final result. In the vast majority of cases this can be viewed as amonoid.From: “Scala With Cats”, by Noel Welsh & Dave Gurnell
I can almost guarantee that nobody who writes Spark jobs for a living cares what a monoid is.
Of course: Having a shared language is important, and maybe I’m just dense; but it took me >1,000 pages to understand the basics (the ones I’m talking about in this post), whereas I can probably pick up the gist of say, go, in an afternoon.
And it’s not even that I don’t find the topic interesting - but even I, with all my weirdness of digging into obscure stuff to write blog articles about it, find myself hard-pressed to learn a new language (as in, a lingo) to learn a new language.
Book Reviews↑
Which leads me to the final part of this exercise, which is a brief review two very different books I read before writing this: “Functional Programming Simplified”, by Alvin Alexander[1], and “Essential Scala”, by Noel Welsh and Dave Gurnell [2].
[1] https://alvinalexander.com/scala/functional-programming-simplified-book/
[2] https://books.underscore.io/essential-scala/essential-scala.html
Essential Scala↑
Essential Scala was the first book recommended to me. It’s free, concise, and gives a tour about the most important language features.

(Credit: Credit: underscore.io)
This book is aimed at programmers learning Scala for the first time. We assume you have some familiarity with an object-oriented programming language such as Java, but little or no experience with functional programming.
…
If you are an experienced developer taking your first steps in Scala and want to get up to speed quickly then this is the book for you.
Its approach is a mix of going through the language features systematically, followed by many exercises at the end of each sub-chapter. The examples are often re-used, so it’s highly advised to actually do the exercises or, at least, read the provided solution. I’m a big fan of “learning by doing”, and the examples actually made sense.
In terms of criticism, however, I’m missing one big thing, and that is the “So What?”. The “So What” is often missing in many technical topics, because authors assume that you already have a deep desire to learn about a topic and that you, presumably, have figured out why. FP, as establishes, hides these benefits behind a thick veil of stuffy terminology.
Allow me to give an example:
We’re going to look at modelling data and learn a process for expressing in Scala any data model defined in terms of logical ors and ands. Using the terminology of object-oriented programming, we will express is-a and has-a relationships. In the terminology of functional programming we are learning about sum and product types, which are together called
algebraic data types
It then goes on to write a domain model - the cat and dog one, no less - but fails to describe why I just can’t use normal OOP modelling in Scala. Because, you know, I can: I can just write classes, abstract classes, traits, and all the fun things Java already has. This chapter also jumps at you with “Product Types” vs “Sum Types” and handy little charts that I already forgot. And yes, that is, indeed, the academic way:
The basic idea behind algebraic data types (ADTs) is to represent relations between data, specifically the notions of “and” and “or”. And AND type is one that represents multiple types combined together, and an OR type represents a value that is exactly one of many possible types.
It took a coworker to tell me why I should care, and here’s my (not his) summary of why: Because ADTs are like enums on steroids, they actually describe what’s going on (rather than using catch-alls), they keep the benefits of clear pattern matching and immutability, and the compiler can use all that stuff to help you out (rarely do you just use String when you can newtype). There’s more, but as far as I’m concerned, that’s the gist of it.
Here’s an example:
sealed trait HttpStatus { val code: Int}
@newtypefinal case class OkStatus(code: 200) extends HttpStatus
@newtypefinal case class NotFoundStatus(code: 404) extends HttpStatus
@newtypefinal case class UserFacingMessage(value: String)
def respondToUser(httpStatus: HttpStatus): UserFacingMessage = httpStatus match { case OkStatus(_) => UserFacingMessage("All is good!") case NotFoundStatus(s) => UserFacingMessage(s"Here, give this to tech support: $s") case _ => UserFacingMessage("I don't even know") }This model is wonderfully self explanatory: There’s different HttpStatus, and all of them have a code as an int; in the method respondToUser, we get an HttpStatus - we don’t get just an int and check if status == 400 or if status == STATUS_BAD (…) - and return a message that, while just a wrapper around String, clearly says is user-facing.
A function like this:
@newtypefinal case class InternalMessage(value: String) //, code: HttpStatus, error: Throwable)def respondToBugReporter(value: InternalMessage) // ...Can be gate-kept by the compiler, so that neither a user gets to see a scary stacktrace, nor does the log aggreator get to see useless, user-facing fluff, despite all of them being really just a String (even though InternalMessage could have more details, as indicated).
Once you figure out why should you care though, “Essential Scala” is a wonderful resource to get your hands dirty - but I highly recommend going at it knowing at list some theoretical Haskell, and not just e.g. Java.
Functional Programming Simplified↑
“Functional Programming Simplified” clocks in at >700 pages and is much, much more verbose than “Essential Scala”. Some people will hate that, while I personally dig it.

My copy of FP Simplified.
Frankly, the book’s approach of “I’m not just telling you what, I’m telling you why, and I won’t take myself too seriously” is something that works in good harmony with my brain. Quote:
“Oh cool. In mathematics we call that sort of thing ‘map’. Then he pats you on the back, whishes you luck, and goes back to doing whatever it is mathematicians are doing.
…
If a normal human being had discovered this technique, they might have come up with a name like
ThingsThatCanBeMappedover, but a mathematician discovered it and came up with the name “Functor”.
And this is the very approach that I needed: These quotes are out of context and are preceded by several chapters on the why alongside the how - once the word “Functor” shows up, you’ve already seen them in action several times.
Same with “Monad” - the author simplifies it to (and I’m not quoting here) “a thing that you can use in a for expression, even though that’s not quite accurate” - but it’s close enough.
“Close enough” is a Software Engineering mantra that some folks despite, and others love - I’m firmly in the former camp. Yes, there are many, many things where precision, proofs, and very, very careful consideration are mandatory and not optional (imagine a “transactional” database that isn’t transactional and looses the information about your cash deposit at an ATM or an encryption tool that doesn’t actually encrypt your data!). But a Beginner’s book is not the place for those!
Quotes like these turned the dreaded, new lingo into something I could not only put in context, but now also actually use - and I love it. It reminds me of a series of books I quite liked (despite earlier comments on programming books), due to their didactic style (“Head First Java” by Kathy Sierra & Bert Bates).
In terms of criticism I’d say two things: First of all, the verbosity and lack of exercises despite that won’t be for everyone. The author does tell you to skip chapters, but the book’s style doesn’t lend itself well to using is as an almanac, but rather as a “head to cover” read. Second, and that’s the reality of life, the author starts talking about topics (cats, Akka actors, Futures) but runs out of time - I’m not sure if those chapters are necessary. You’ve seen quotes from “Scala with Cats” above (and I also have “Practical FP in Scala” by Garbiel Volpe here), where the type of advanced-topic book might simply make more sense.
Conclusion↑
I recommend both books, and I’m sure glad I’ve read both.
Other than that, I’m not sure I’ve told you anything groundbreaking, so I’ll just re-iterate:
Scalais notSpark, and knowingSparkdoesn’t mean you knowScala; it hurts, I know, but it’s trueScalacan do a lot; once you get past the wall of gatekeeping, it actually offers some benefits, specifically in the Data Engineering space, such as modelling withADTs, strong types, and immutable data- Functional Programming is more complex than OOP, and much harder to get into; part of that is the lack of approachable literature, since the literature that does exist tells you how, but not “why”
- The “Why” - or even “Why should I care?” question has been a theme -
Scalaisn’t faster thanJava, less-verbose code is often just less maintainable in the long run, so why would I learn it - the benefits are subtle (and the not-so-subtle subtext here is that I’m not yet convinced either!) - We’ve ignored most theoretical benefits functional programming, and rather focussed on Data Engineering as a discipline - and there,
Scalahas something to offer - but as established previously, so hasgo
To sum it up, Scala is actually really cool - some folks just overdo it. Once you get past that, though, you can have a lot of fun, even though I’m struggling with finding the right terms to even get to the correct concepts (“Higher-Kinded Types” vs. “Tagless Final” came up last week), not to mention their pros and cons on the daily.
After that becomes less on an issue, the general dogma works well with my brain: I always liked recursion, immutable values avoid headaches, and the idea of defining how you want to do something by defining the name, input, and output before the implementation (alongside the structure, such as with ADTs) works great for me.
Scala even has a ??? keyword for that:
scala> def add(x: Int, y: Int): Int = ???add: (x: Int, y: Int)IntSo, long story short: Scala, and by proxy, Haskell, are a handful; even though I’ve only scratched the surface in the past month or so, I am somewhat hungry for more - I actually planned on finishing “Scala with Cats” before writing this article, but I figured, I’d never get to it that way. So, maybe you a bit hungry for more as well now.
All development and benchmarking was done under GNU/Linux [PopOS! 21.10 on Kernel 5.15] with 12 Intel i7-9750H vCores @ 4.5Ghz and 32GB RAM on a 2019 System76 Gazelle Laptop