Blog posts tagged with 'cloud''
- How I built a (tiny) real-time Telematics application on AWS
2019-08-07: In 2017, I wrote about how to build a basic, Open Source, Hadoop-driven Telematics application (using Spark, Hive, HDFS, and Zeppelin) that can track your movements while driving, show you how your driving skills are, or how often you go over the speed limit - all without relying on 3rd party vendors processing and using that data on your behalf...
awsbashcloudiotkinesislambdalinuxprogrammingpython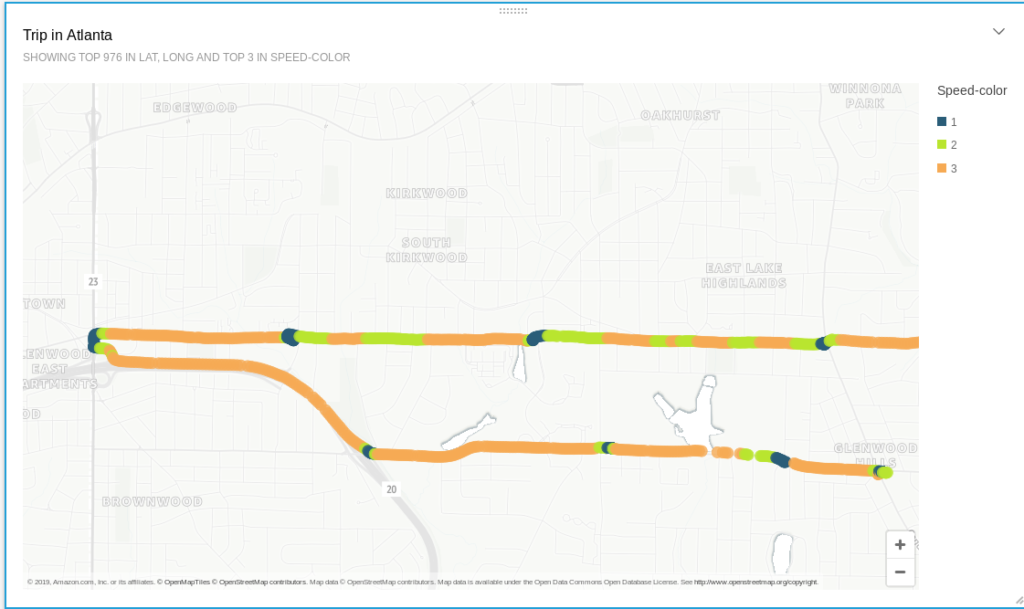
- A look at Apache Hadoop in 2019
2019-07-01: In this article, we'll take a look at whether Apache Hadoop still a viable option in 2019, with Cloud driven data processing an analytics on the rise...
awsazurebig datacloudgoogle cloudhivelinuxprogrammingspark
- Analyzing Reddit’s Top Posts & Images With Google Cloud (Part 2 - AutoML)
2018-10-27: In the last iteration of this article we analyzed the top 100 subreddits and tried to understand what makes a reddit post successful by using Google’s Cloud ML tool set to analyze popular pictures.
analyticsautomlbig datacloudgoogle cloudgcpmachine learningprogrammingpythontensorflowvision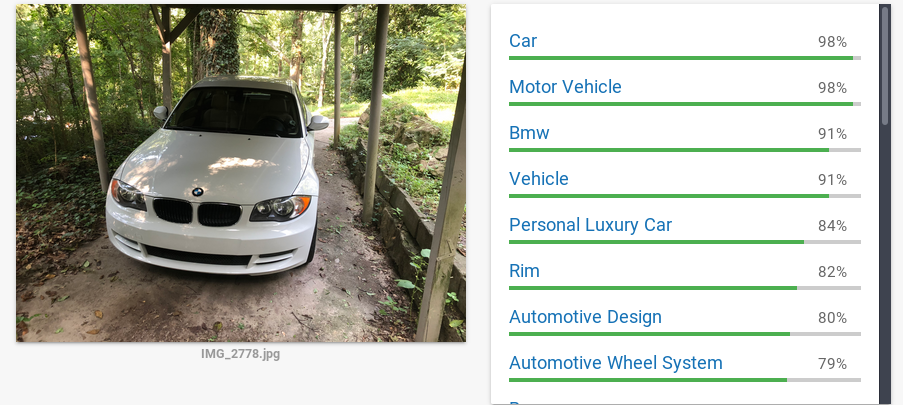
- Analyzing Reddit’s Top Posts & Images With Google Cloud (Part 1)
2018-06-12: In this article (and its successors), we will use a fully serverless Cloud solution, based on Google Cloud, to analyze the top Reddit posts of the 100 most popular subreddits. We will be looking at images, text, questions, and metadata...
analyticsautomlbig datacloudgoogle cloudgcpmachine learningprogrammingpythontensorflowvision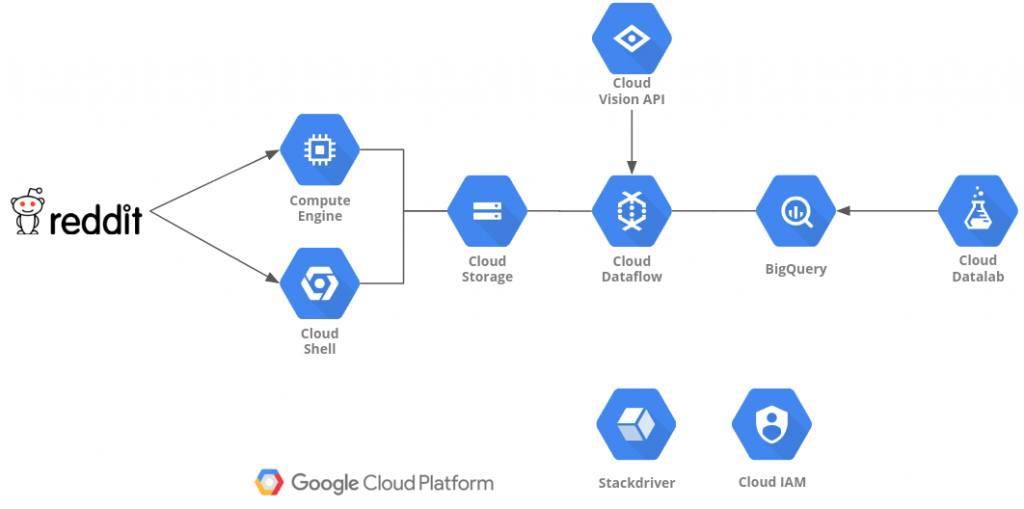
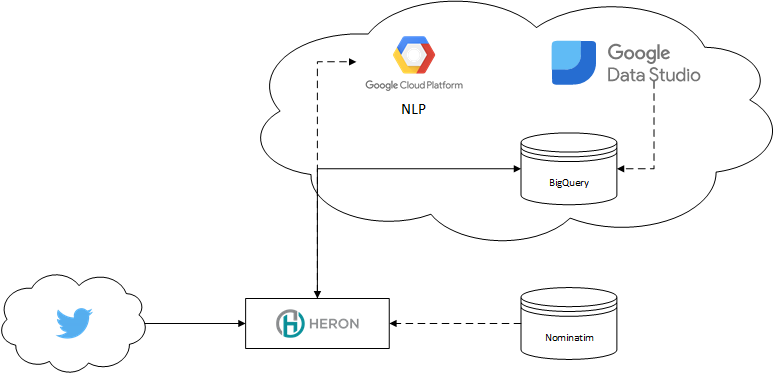
- Analyzing Twitter Location Data with Heron, Machine Learning, Google's NLP, and BigQuery
2018-03-18: In this article, we will use Heron, the distributed stream processing and analytics engine from Twitter, together with Google’s NLP toolkit, Nominatim and some Machine Learning as well as Google’s BigTable, BigQuery, and Data Studio to plot Twitter user's assumed location across the US.
analyticsbig datacloudgoogle cloudgcpmachine learningprogramminghbasenlpheronstormjava